순환 신경망 활용 사례
순환 신경망Recurrent Neural Networks, RNN이 가장 많이 활용되는 사례는 단연 자연어처리NLP가 될 것입니다. 자연어처리에서 문장은 출현 단어의 갯수가 가변적이며 단어들의 출현 순서에 따라 의미가 결정됩니다. 자연어처리에서도 다양한 분야가 존재하는데요. 각 분야에 따라 RNN이 활용되는 방법이 다릅니다. 다음의 표는 활용 타입에 따른 모델 구조와 사용 예제들을 정리한 것입니다.
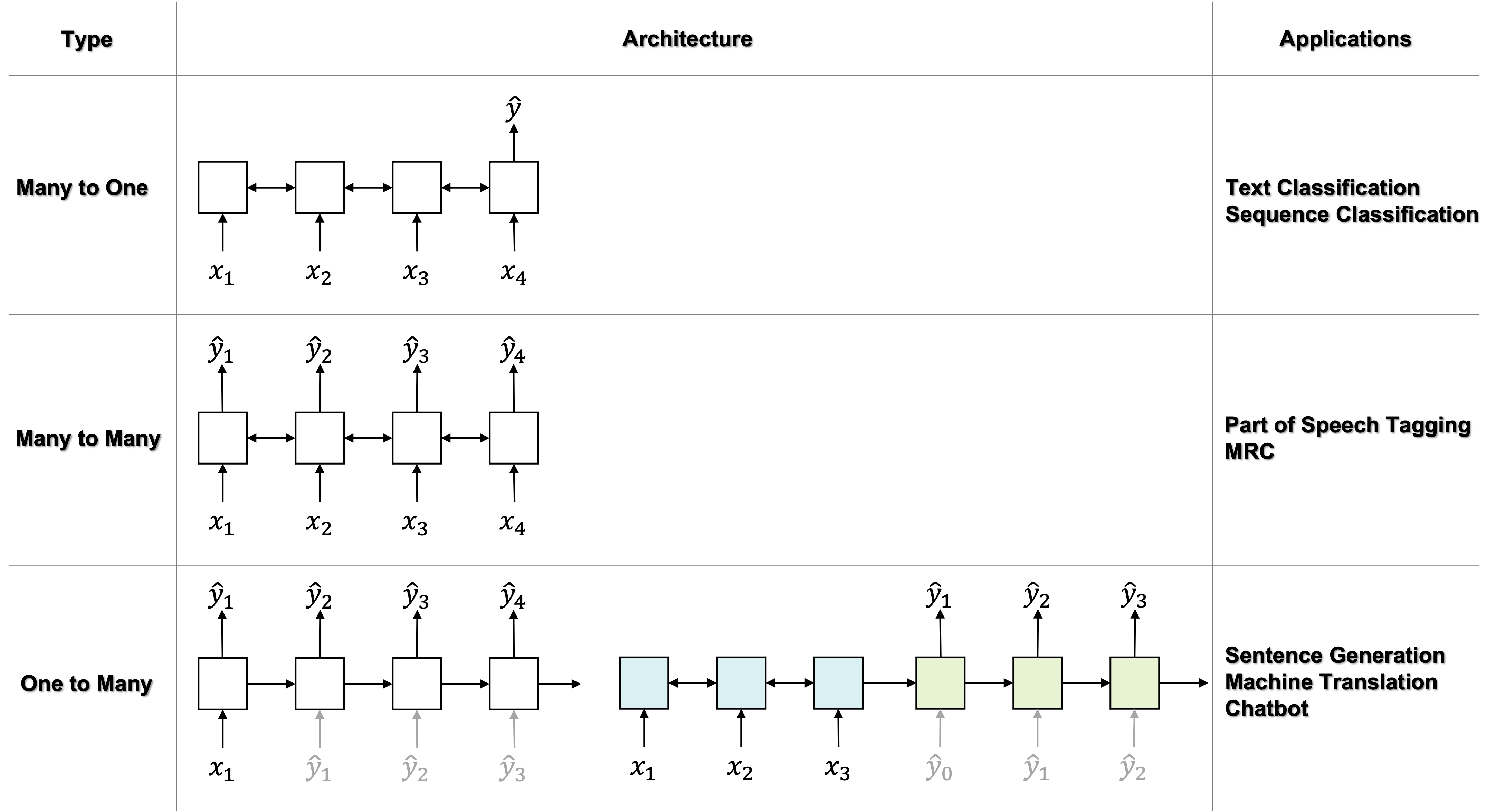
이처럼 입력과 출력의 종류에 따라 활용 타입을 정의할 수도 있지만, 모델링 하고자 하는 대상의 자기회귀auto-regressive 성격 여부에 따라 활용 방법이 달라지기도 합니다. 여기서 자기회귀란 현재 상태가 과거 상태에 의존하여 정해지는 경우를 이릅니다. 따라서 정보 흐름의 방향이 생기게 되고, 우리는 이것을 모델링하기 위해선 단방향 순환 신경망을 사용할 수 밖에 없습니다. 문장 전체를 놓고 문장이 속하는 클래스(e.g. 긍정 or 부정)를 정하는 문제의 경우에는, 이미 분류기에 들어가기 전에 문장 전체가 주어지며, 클래스는 문장 전체에 대해서 단 한번 예측이 수행되기 때문에, 자기회귀 성격을 가진다고 볼 수 없습니다. 다음 표는 자기회귀와 비자기회귀 타입의 모델링에 대해 정리한 것입니다.
| 타입 | 비자기회귀Non-autoregressive | 자기회귀Autoregressive |
|---|---|---|
| 특징 | 현재 상태가 과거/미래 상태를 통해 정해지는 경우 | 현재 상태가 과거 상태에 의존하여 정해지는 경우 |
| 모델링 성격 | 비생성적Non-generative | 생성적Generative |
| 사용 예 | 형태소 분석 태깅, 텍스트 분류text classification | 자연어 생성NLG, 기계 번역machine translation, 챗봇 |
| 활용 모델 구조 | 양방향 순환 신경망 사용 권장 | 양방향 순환 신경망 사용 불가 |
다시 처음에 소개하였던 모델의 입출력 데이터 기준 다대일, 다대다, 일대다 형태에 대해서 정리해보도록 하겠습니다.
다대일 형태
다대일many to one 형태는 우리가 학습할 데이터에서 입력이 순서 정보를 갖고 있고, 출력이 순서 정보가 없는 경우입니다. 가장 쉬운 케이스라고 볼 수 있는데요. 앞서 설명대로라면 이 케이스는 비자기회귀 성격을 갖는다고 볼 수 있습니다. 다음 그림은 다대일 형태를 학습할 때, 모델 구조와 손실 함수 형태를 정리한 것입니다.
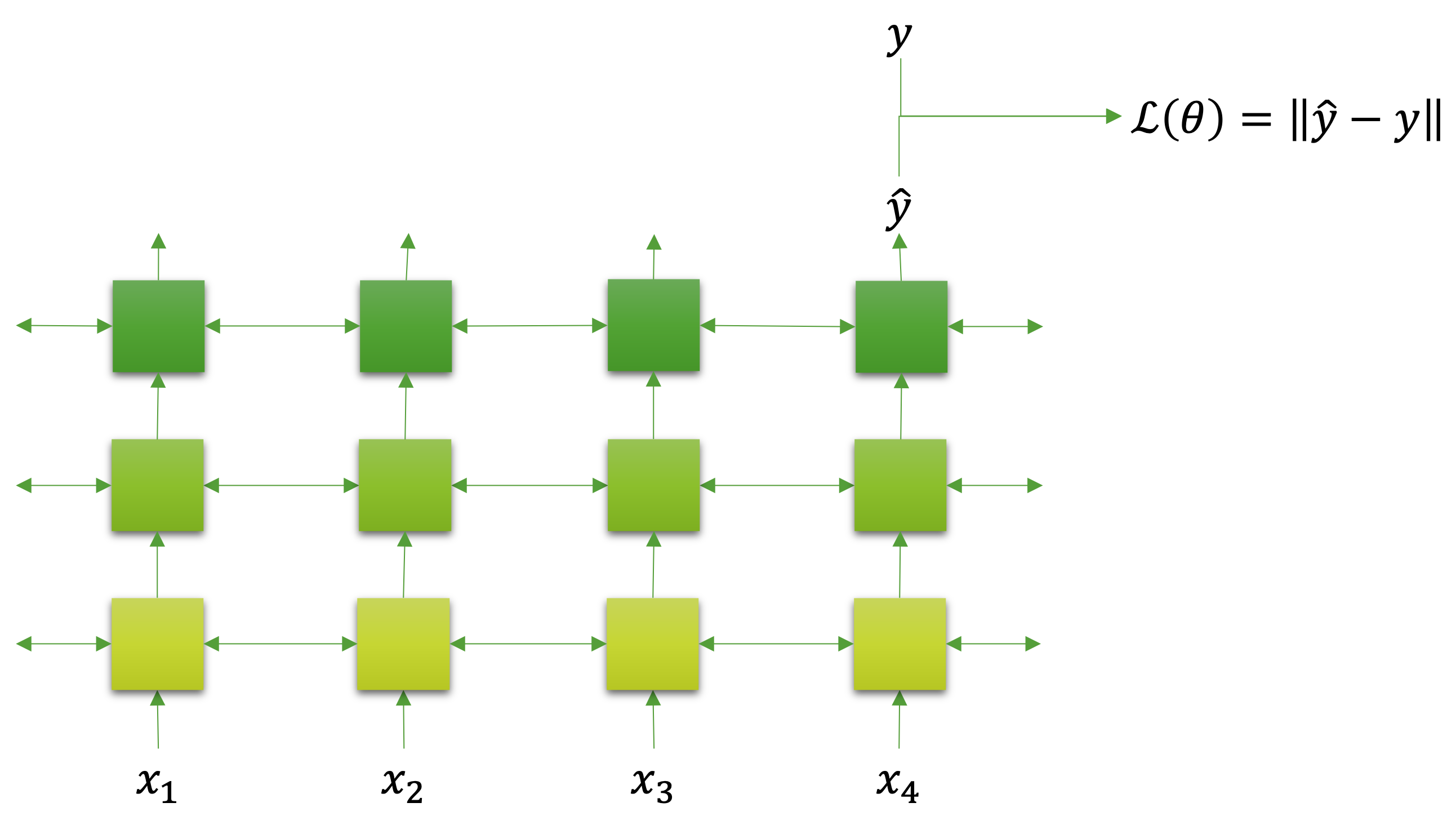
그림에서 볼 수 있듯이 양방향 순환 신경망을 사용할 수 있으며, 보통 가장 마지막 순서 출력[1]을 활용하여 모델의 예측 값 $\hat{y}$ 으로 삼고 원래 목표 값인 $y$ 와 비교하여 손실 값을 계산합니다. 텍스트 분류가 가장 좋은 예제라고 볼 수 있는데요. 텍스트 문장을 정해진 기준에 따라 쪼개어[2] 순환 신경망의 입력으로 삼아 각 순서에 맞게 나누어 넣어줍니다. 그럼 마지막 계층의 마지막 순서에서 나온 출력을 비선형 활성 함수, 선형 계층, 소프트맥스softmax 함수를 거치도록 하여 각 클래스별 확률 값으로 변환할 수 있습니다. 그리고 마지막으로 분류 문제이기 때문에 교차 엔트로피cross entropy 손실 함수를 통과시켜 손실 값을 구할 수 있을 것입니다.
[1]: 가장 처음 순서 출력을 활용해도 괜찮습니다.
[2]: 자연어처리에서 이 과정을 분절tokenization이라고 부릅니다.
다대다 형태
다음은 입력과 출력 모두 순서 정보를 갖는 데이터가되는 다대다 형태입니다. 다만 여기서 중요한 점은 입력과 출력의 순서 갯수가 똑같아야 하며, 출력의 각 순서가 입력에 대응되는 형태여야 합니다. 만약 순서 갯수가 다르거나 대응이 다르게 된다면 마지막 일대다 형태가 되어야 합니다. 그리고 앞서와 마찬가지로 비자기회귀 성격을 갖습니다. 이것은 다음 그림을 통해 쉽게 확인할 수 있는데요.
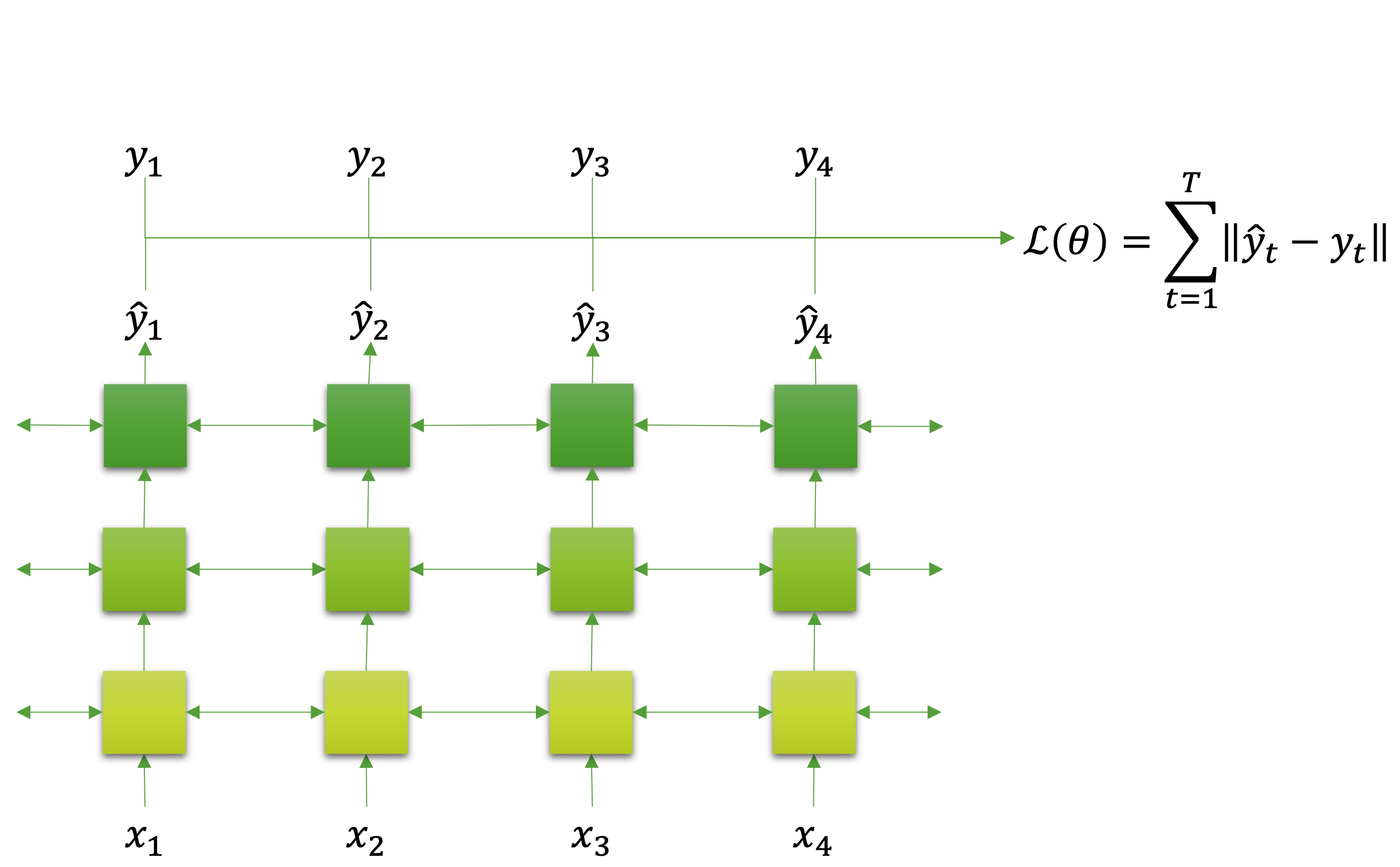
각 순서의 입력 $x_t$ 마다 대응되는 목표 값 $y_t$ 가 존재하는 것을 볼 수 있고, 모델에서도 각 입력에 대응되는 $\hat{y}_t$ 가 출력되고 있는 것을 볼 수 있습니다. 그럼 모든 순서의 출력 값과 목표 값의 차이를 합쳐서 손실 값을 계산할 수 있습니다. 이러한 다대다 형태의 가장 흔한 에제는 형태소 분석이 됩니다. 문장 내 토큰token들에 대해서 각각 형태소가 태깅되어야 하기 때문에, 입력 순서들에 1:1로 대응되는 출력 값들이 존재해야 하기 때문입니다.
일대다 형태
다음은 생성 모델generative model에 많이 활용되는 형태인 일대다 형태에 대해 이야기해보도록 하겠습니다. 일대다의 경우에는 입력의 형태보다는 출력의 형태가 중요합니다. 입력의 순서에 1:1 대응되는 것이 아닌, 출력에 순서 정보가 존재하는 데이터라면 대부분 일대다 문제가 적용될 수 있을텐데요. 가장 흔한 예제는 자연어생성Natural Langauge Generation, NLG 문제인 기계 번역machine translation이나 챗봇 등이 있습니다. 또는 이미지가 주어졌을 때, 해당 이미지를 설명하는 문장을 생성하는 문제도 여기에 해당될 것입니다. 다음의 그림을 보면 좀 더 일대다 형태에 대해서 쉽게 이해할 수 있을텐데요.
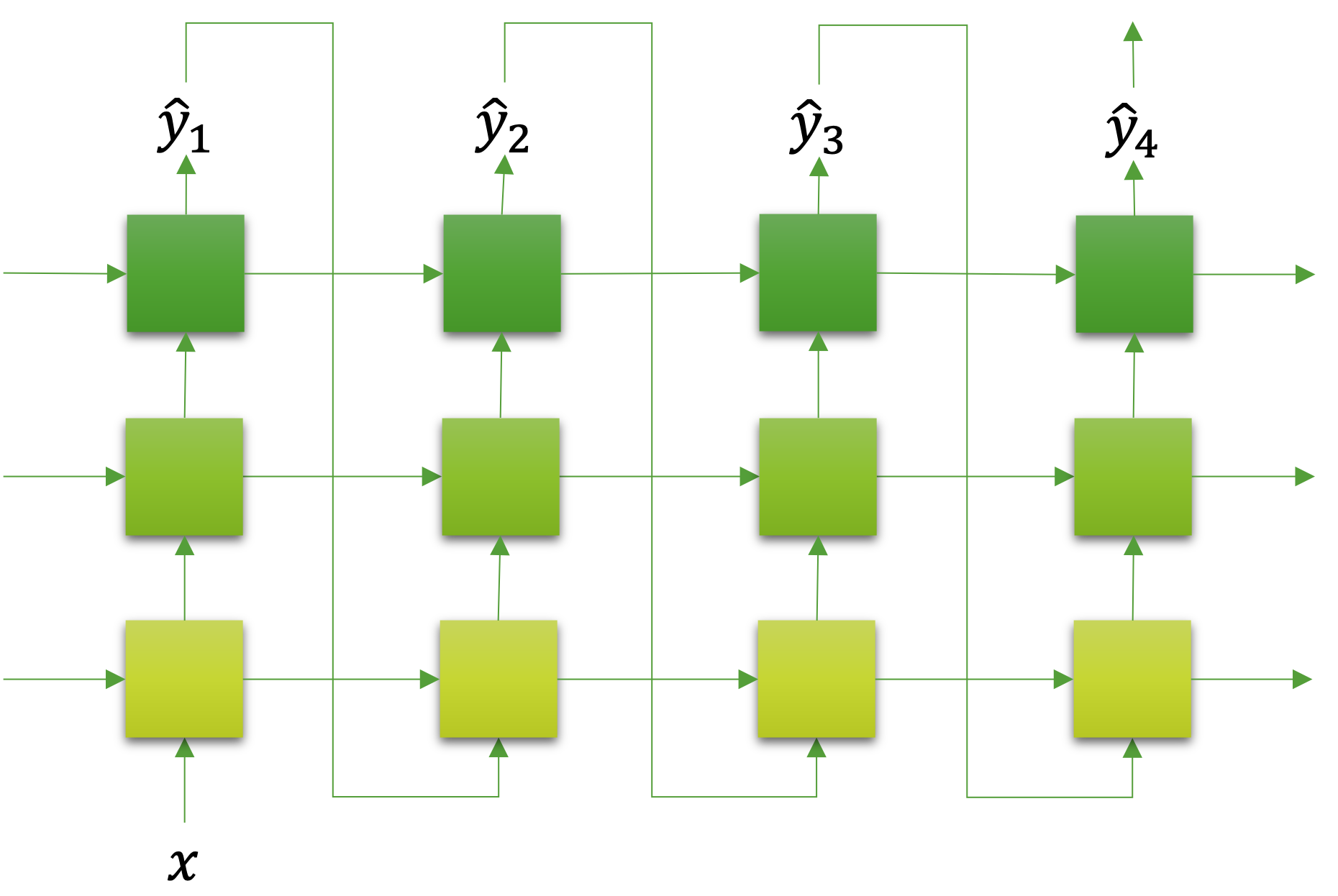
앞서까지와 사뭇 다른 형태를 띄고 있음을 알 수 있습니다. 가장 중요한 점은 일단 모델의 입력이 $x$ 하나로 되어 있는것을 볼 수 있고, 이후 순서에는 이전 순서의 모델의 출력 값 $\hat{y}{t-1}$ 이 넣어지는 것을 확인할 수 있습니다. 따라서 $y_0=x$ 라고 가정한다면, $\hat{y}_t$ 는 $\hat{y}{t-1}$ 의 영향을 받아서 자기회귀auto-regresive 성격을 갖게 되는 것을 볼 수 있습니다.
따라서 만약 입력 $x$ 에 이미지에 대한 정보를 넣어줄 경우 이미지에 대한 설명 문장을 생성할 수 있을 것이고, 한글 문장에 대한 정보가 들어있다면 대응되는 영어 번역 문장을 생성할 수 있을 것입니다. 또는 질문 문장에 대한 정보가 들어있었다면 이에 대한 대답 문장을 생성할 수 있을 것입니다.
이러한 문제를 해결하기 위해서는 다음과 같이 다대일 형태와 일대다 형태가 결합하는 시퀀스 투 시퀀스Sequence to Sequence, Seq2Seq를 활용할 수도 있습니다. 다음의 그림은 Seq2Seq를 도식화 한 것입니다.
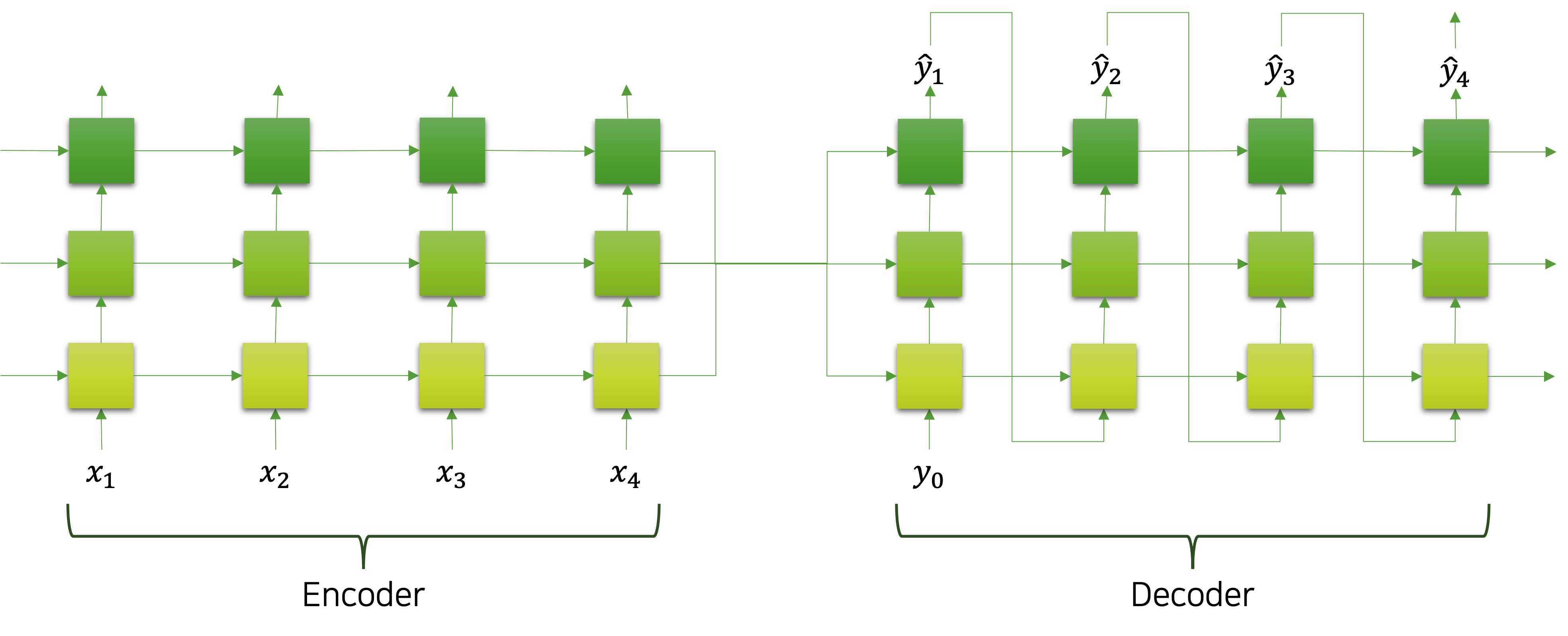
그림의 왼쪽 부분은 다대일 형태의 인코더encoder가 되어 문장을 입력으로 받아서 하나의 벡터 형태로 정보를 압축한다면, 다대일 형태의 디코더decoder는 정보를 받아서 순서 데이터인 문장으로 생성해내는 역할을 수행할 것입니다. 이처럼 각 형태들은 자체가 전체 모델로 활용되기도 하지만, 전체 모델을 구성하기 위한 서브 모듈sub-module로 활용되기도 합니다. 독자분들도 각 형태를 잘 숙지하시고, 필요에 따라 순환 신경망을 조합하여 사용한다면 더욱 쉽게 문제를 해결할 수 있을 것입니다.