테스트셋 구성하기
앞서 이번 챕터를 시작할 때, 좋은 평가란 무엇인가 이야기하였는데요. 결국 좋은 평가의 핵심은 얼마나 객관적으로 평가를 진행하였는지가 중요합니다. 만약 평가를 수행할 때, 한쪽 모델에게 유리한 환경이 조성되면 객관적인 평가가 진행되었다고 볼 수 없겠지요.
테스트셋의 필요성
이러한 관점에서, 이전 장에서는 검증 데이터셋validation dataset을 구성하여 모델의 오버피팅 여부를 확인하는 방법에 대해서 이야기하였습니다만, 아직까지도 사실은 반쪽짜리 학습/평과 과정이었다고 볼 수 있습니다. 왜냐하면 우리는 학습을 종료하고 수많은 에포크epoch에서 나온 모델(가중치 파라미터weight parameter)들 중에서, 검증 손실 값이 가장 낮았던 모델을 선택하기 때문입니다. 또한 보통 하이퍼파라미터의 경우에도 검증 손실 값을 낮추는 방향으로 튜닝되기 때문입니다. 따라서 이것은 검증 데이터셋을 활용한 하이퍼파라미터hyper-parameter(어떤 에포크를 선택할 것인지도 포함하여) 학습 과정으로 볼 수 있으며, 검증 데이터셋을 활용하여 최종 평가를 수행한다면 평가 데이터를 이미 모델에게 보여준 것이나 다름없기 때문입니다. 즉, 평가를 위한 테스트셋testset으로 검증 데이터셋을 활용한다면, 우리의 모델은 테스트셋에 오버피팅 될 것입니다. 그리고 베이스라인 모델들에게는 불공정한 평가가 되는 것이지요.
데이터 나누기
따라서 우리는 최종적으로 학습을 위한 데이터셋과 검증을 위한 데이터셋, 마지막으로 평가(테스트)를 위한 데이터셋을 따로 구성해야 합니다.

애초에 테스트를 위한 데이터셋을 손수 엄선하여 구성할 수도 있지만, 만약 임의로 데이터셋을 랜덤하게 나누어 구성한다면 마찬가지로 편향과 중복이 없도록 주의해야 합니다.[1] 이때 3가지 데이터셋의 비율은 보통 8:1:1에서부터 6:2:2로 구성합니다.
[1]: MNIST와 같은 일부 데이터셋들은 애초에 테스트 데이터를 따로 구성해 놓기도 합니다.
정리
중요한 개념이므로 이야기가 길어졌는데요. 앞서 다룬 내용들을 정리하면 다음과 같이 표로 나타낼 수 있습니다.
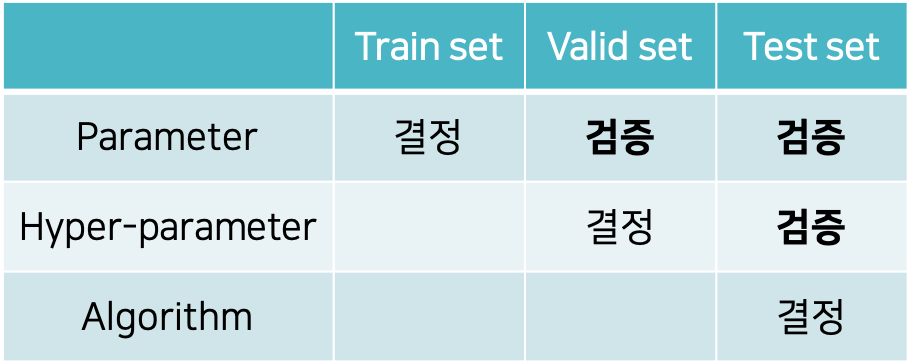
우리는 학습 데이터셋을 통해 가중치 파라미터를 결정(학습)할 수 있으며, 검증 데이터셋과 테스트 데이터셋을 통해 오버피팅과 같은 정합성 여부를 확인할 수 있습니다. 하이퍼파라미터의 경우, 경사하강법과 같은 최적화 방법을 통해 결정될 수 없기 때문에 사용자에 의해 손으로 결정되는 작업이 수반되어야 합니다. 따라서 대부분의 하이퍼파라미터들은 검증 데이터셋을 통해 결정되며, 테스트셋을 통해서 검증을 수행할 수 있습니다. 알고리즘을 결정한다는 것은 여러가지 베이스라인을 비롯한 모델 구조나 학습 기법들 중에서 어떤 구조나 기법이 가장 좋은지 결정하는 것을 의미합니다. 어쨌든 결국 테스트 데이터셋을 통한 평가를 통해 최고 성능의 알고리즘을 선택해야 하기 때문입니다.