실습: Deep Regression
데이터 준비
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
필요한 라이브러리들을 불러오고, 데이터도 불러옵니다. 출력 값은 TARGET 속성으로 저장되도록 합니다.
from sklearn.datasets import load_boston
boston = load_boston()
df = pd.DataFrame(boston.data, columns=boston.feature_names)
df["TARGET"] = boston.target
보스턴 주택 가격 데이터셋은 13개의 속성을 가지며, 506개의 샘플로 구성되어 있습니다. 일부 속성만을 활용하여 선형 회귀를 학습하였던 것과 달리, 이번에는 전체 속성들을 활용하여 심층신경망을 학습시켜보도록 하겠습니다. 이에 앞서, 좀 더 쉬운 수월한 최적화 및 성능 향상을 위해 표준 스케일링standard scaling을 통해 입력 값을 정규화하도록 하겠습니다.
scaler = StandardScaler()
scaler.fit(df.values[:, :-1])
df.values[:, :-1] = scaler.transform(df.values[:, :-1]).round(4)
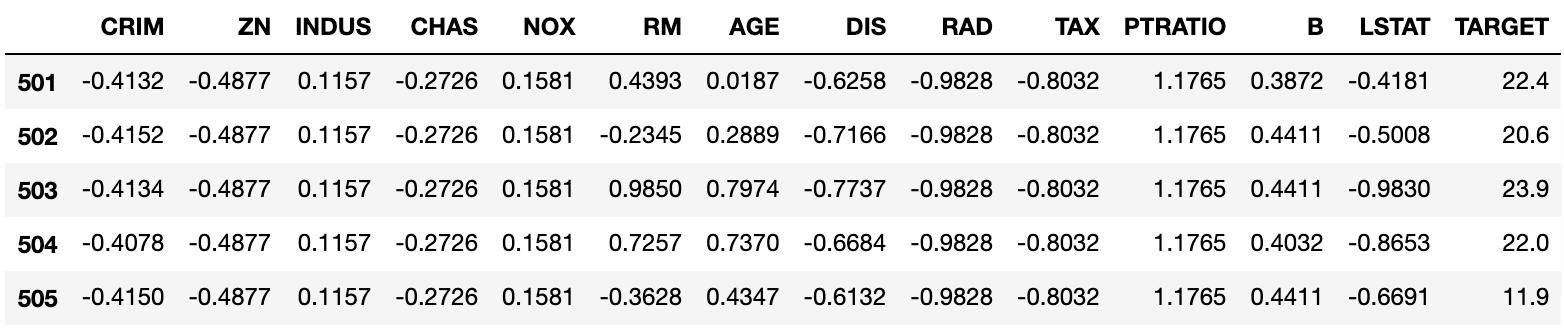
df.tail()
정규화를 하는 이유는 무엇일까요? 앞서는 날 것 그대로의 값을 활용하여 학습을 수행하였습니다. 이러한 경우에는 각 열column의 값들이 다른 범위와 분포를 갖기 때문에 신경망이 이것을 학습할 때 어려움을 겪을 수 있습니다. 극단적인 예를 들어 두 개의 열이 존재하는 데이터셋에서 첫 번째 열의 범위는 -10,000 에서 10,000 이고, 두 번째 열의 범위는 0 에서 10 이라고 했을 때, 첫 번째 열의 값이 10의 크기로 변하는 것은 매우 작은 변화이지만, 두 번째 열의 범위에서는 양 극단을 오고가는 크기의 변화가 됩니다. 잘 학습된 신경망에서는 이러한 각 열의 특징에 따라 알맞은 계수coefficient를 곱해주어 상쇄시킬 수 있지만, 처음 학습하는 신경망 입장에서는 잘 정규회된 데이터셋을 배우는 것에 비해 어려운 일이 될 수 있습니다. 따라서 적절한 정규화 과정을 통해 신경망의 최적화를 수월하게 만들 수 있습니다.
이때 다양한 정규화 방법이 존재합니다. 방금 사용한 표준 스케일링 같은 방법에서부터, 최소/최대 스케일링min/max scaling과 같은 다양한 정규화 방법들이 존재하기 때문에, 우리는 정규화를 적용하기에 앞서 데이터셋 분포의 특징을 파악하고 어떤 정규화 방법이 가장 어울릴지 결정해야 합니다. 여기서는 보스턴 주택 가격 데이터셋의 각 열들이 정규분포normal distribution를 따른다고 가정하고, 표준 스케일링을 적용하였습니다. 다음 테이블은 표준 스케일링을 적용한 결과를 나타냅니다.
학습 코드 구현
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
학습에 필요한 패키지들을 불러오고, 판다스Pandas에 저장된 넘파이 값들을 파이토치 텐서로 변환하여 입력 텐서 x와 출력 텐서 y를 만듭니다.
data = torch.from_numpy(df.values).float()
y = data[:, -1:]
x = data[:, :-1]
학습에 필요한 설정 값들을 정해줍니다. 독자분들도 이 설정값들을 바꿔가며 학습해보면 더 많은 경험을 쌓을 수 있을 것입니다.
n_epochs = 200000
learning_rate = 1e-4
print_interval = 10000
이제 심층신경망deep neural networks을 정의합니다. 앞서와 마찬가지로 nn.Module을 상속받아 MyModel 이라는 나만의 모델 클래스를 정의합니다. 그리고 이 나만의 심층신경망은 4개의 선형 계층과 비선형 함수를 갖도록 하겠습니다. __init__ 함수를 살펴보면, 선형 계층은 각각 linear1, linear2, linear3, linear4 라는 이름을 가지도록 선언하였고, 비선형 활성함수는 ReLU를 사용하려합니다. 다만, 선형 계층들은 각각 다른 가중치 파라미터weight parameter들을 가질 것이므로 다른 객체로 선언하는 것과 달리, 비선형 활성함수의 경우에는 학습되는 파라미터를 갖지 않았기 때문에 모든 계층에서 동일하게 동작하므로 한 개만 선언하여 재활용하도록 할 것입니다. 그리고 각 선형계층의 입출력 크기는 최초 입력 차원(input_dim)과 최종 출력 차원(output_dim)을 제외하고는 임의로 정해주었습니다.[1]
그리고 forward 함수에서는 앞서 선언된 내부 모듈들을 활용하여 피드포워드feed-forward 연산을 수행할 수 있도록 합니다. x라는 샘플 갯수 곱하기 입력차원 (batch_size, input_dim) 크기의 2차원 텐서가 주어지면, 최종적으로 샘플 갯수 곱하기 출력차원 (batch_size, output_dim) 크기의 2차원 텐서로 뱉어내는 함수가 될 것입니다. 여기서 input_dim과 output_dim은 __init__ 함수에서 미리 입력을 받는 것을 볼 수 있습니다. 앞서 이론에서 설명한 것처럼 마지막 계층에는 활성함수를 씌우지 않는 것에 주의하세요.
class MyModel(nn.Module):
def __init__(self, input_dim, output_dim):
self.input_dim = input_dim
self.output_dim = output_dim
super().__init__()
self.linear1 = nn.Linear(input_dim, 3)
self.linear2 = nn.Linear(3, 3)
self.linear3 = nn.Linear(3, 3)
self.linear4 = nn.Linear(3, output_dim)
self.act = nn.ReLU()
def forward(self, x):
# |x| = (batch_size, input_dim)
h = self.act(self.linear1(x)) # |h| = (batch_size, 3)
h = self.act(self.linear2(h))
h = self.act(self.linear3(h))
y = self.linear4(h)
# |y| = (batch_size, output_dim)
return y
model = MyModel(x.size(-1), y.size(-1))
print(model)
마지막 라인과 같이 모델을 출력하면 다음과 같이 잘 정의된 모델을 볼 수 있습니다.
MyModel(
(linear1): Linear(in_features=13, out_features=3, bias=True)
(linear2): Linear(in_features=3, out_features=3, bias=True)
(linear3): Linear(in_features=3, out_features=3, bias=True)
(linear4): Linear(in_features=3, out_features=1, bias=True)
(act): ReLU()
)
앞서와 같은 방법으로 직접 나만의 모델 클래스를 정의하는 방법도 아주 좋은 방법입니다. 하지만 지금은 모델 구조model architecture가 매우 단순한 편입니다. 입력 텐서를 받아 단순하게 순차적으로 앞으로 하나씩 계산해나가는 것에 불과하기 때문입니다. 이 경우에는 나만의 모델 클래스를 정의하는 대신, 다음과 같이 nn.Sequential 클래스를 활용하여 훨씬 더 쉽게 모델 객체를 선언할 수 있습니다. 다음은 앞서 MyModel 클래스와 똑같은 구조를 갖는 심층신경망을 nn.Sequential 클래스를 활용하여 정의하는 모습입니다. 단순히 내가 원하는 연산을 수행할 내부 모듈들을 nn.Sequential을 생성할 때, 순차적으로 넣어주는 것을 볼 수 있습니다. 당연한 것이지만 앞 쪽에 넣은 모듈들의 출력이 바로 뒷 모듈의 입력에 될 수 있도록, 내부 모듈들의 입출력 크기를 잘 적어주어야 할 것입니다.
model = nn.Sequential(
nn.Linear(x.size(-1), 3),
nn.LeakyReLU(),
nn.Linear(3, 3),
nn.LeakyReLU(),
nn.Linear(3, 3),
nn.LeakyReLU(),
nn.Linear(3, 3),
nn.LeakyReLU(),
nn.Linear(3, y.size(-1)),
)
print(model)
모델을 출력한 내용에서 아까와 다른 점이라고 한다면, LeakyReLU를 사용하였고, 하나의 LeakyReLU를 재활용하는 대신 매번 새로운 객체를 넣어준 것을 볼 수 있습니다.
Sequential(
(0): Linear(in_features=13, out_features=3, bias=True)
(1): LeakyReLU(negative_slope=0.01)
(2): Linear(in_features=3, out_features=3, bias=True)
(3): LeakyReLU(negative_slope=0.01)
(4): Linear(in_features=3, out_features=3, bias=True)
(5): LeakyReLU(negative_slope=0.01)
(6): Linear(in_features=3, out_features=3, bias=True)
(7): LeakyReLU(negative_slope=0.01)
(8): Linear(in_features=3, out_features=1, bias=True)
)
이렇게 선언한 모델의 가중치 파라미터들을 옵티마이저optimizer에 등록합니다.
optimizer = optim.SGD(model.parameters(),
lr=learning_rate)
그럼 이제 모델을 학습할 준비가 끝났습니다. 본격적으로 심층신경망을 통해 회귀regression를 수행해보도록 하겠습니다. n_epochs 만큼 for 반복문을 수행합니다. 반복문 내부에는 피드포워드feed-forward 및 손실loss 계산을 하고, 역전파back-propagation와 경사하강gradient descent을 수행하도록 구성되어 있습니다.
for i in range(n_epochs):
y_hat = model(x)
loss = F.mse_loss(y_hat, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % print_interval == 0:
print('Epoch %d: loss=%.4e' % (i + 1, loss))
print_interval 만큼 출력을 하도록 되어있으므로, 이 코드를 실행하면 다음과 같이 학습 결과를 확인할 수 있을 것입니다. 약 1.4 정도에서 시작한 손실 값은, 0.74 정도까지 줄어드는 것을 볼 수 있습니다. 손실 값이 줄어드는 추세를 보았을 때, 학습을 더 진행한다면 손실 값이 더 떨어질 여지는 충분해 보입니다.
Epoch 5000: loss=1.3951e+01
Epoch 10000: loss=1.1192e+01
Epoch 15000: loss=9.7621e+00
Epoch 20000: loss=9.3217e+00
Epoch 25000: loss=8.9595e+00
Epoch 30000: loss=8.7619e+00
Epoch 35000: loss=8.6107e+00
Epoch 40000: loss=8.4628e+00
Epoch 45000: loss=8.2988e+00
Epoch 50000: loss=8.1238e+00
Epoch 55000: loss=7.9395e+00
Epoch 60000: loss=7.8030e+00
Epoch 65000: loss=7.7524e+00
Epoch 70000: loss=7.7000e+00
Epoch 75000: loss=7.6094e+00
Epoch 80000: loss=7.5361e+00
Epoch 85000: loss=7.4911e+00
Epoch 90000: loss=7.4616e+00
Epoch 95000: loss=7.4345e+00
Epoch 100000: loss=7.4097e+00
[1]: 각 선형 계층의 입출력 크기는 모델의 성능을 높이기 위해서는 튜닝되어야 합니다.
결과 확인
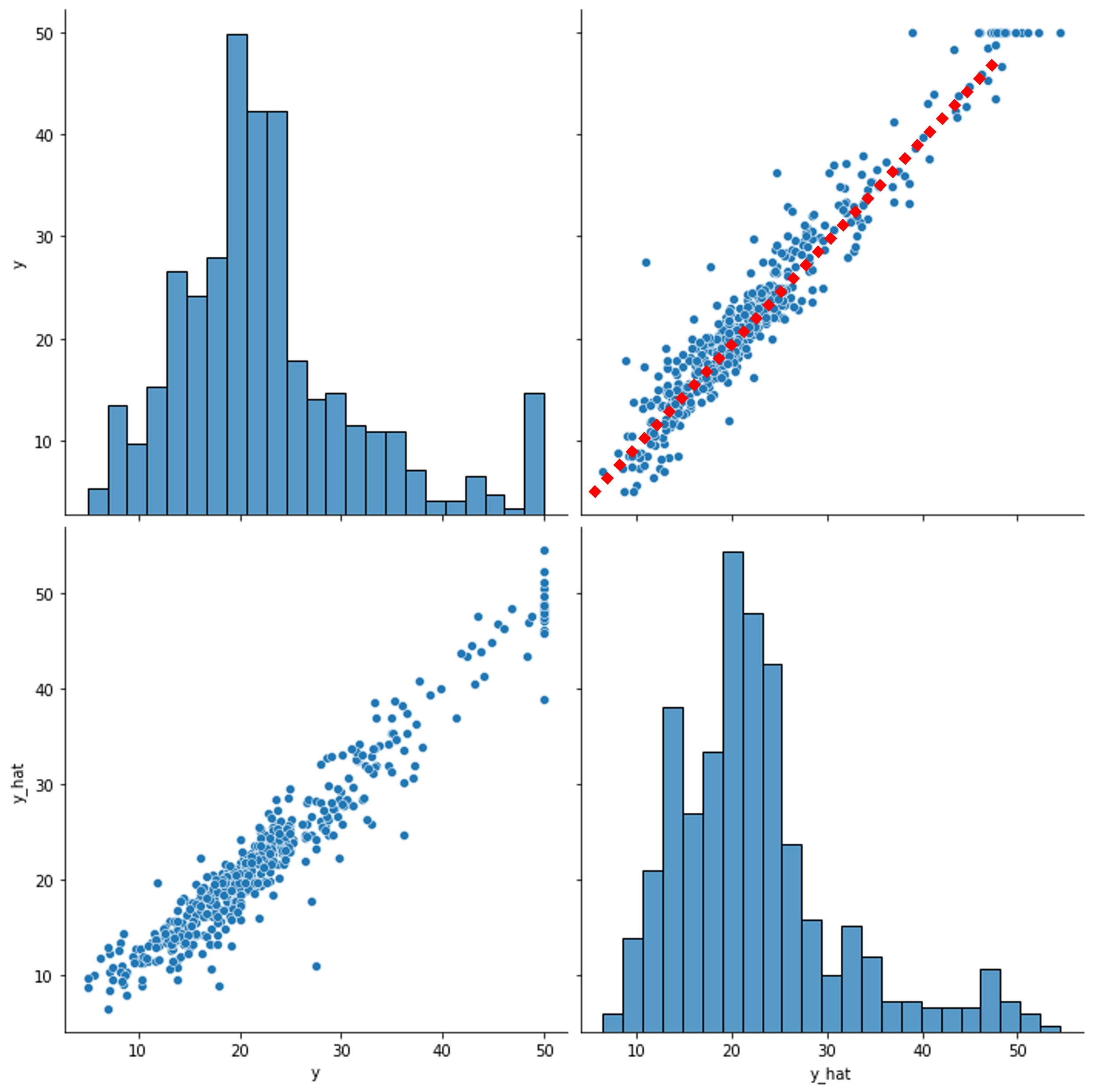
앞서 학습한 모델이 얼마나 잘 학습되었는지 시각화를 통해 확인해보도록 하겠습니다. 정답 텐서 y와 예측값 텐서 y_hat 을 이어붙이기concatenation한 다음에, 판다스Pandas 데이터프레임에 넣어 페어플랏pairplot을 출력한 모습입니다.
df = pd.DataFrame(torch.cat([y, y_hat], dim=1).detach().numpy(),
columns=["y", "y_hat"])
sns.pairplot(df, height=5)
plt.show()
우상단의 빨간 점선을 따라 값들이 잘 분포하는 것을 볼 수 있습니다. 이 빨간 점선에서 멀어질수록 잘못된 예측을 하고 있는 것입니다. 또한 좌상단의 그림에서 y의 분포를 확인할 수 있는데, y_hat의 경우에도 y와 비슷하게 왼쪽으로 중심이 살짝 치우친 분포를 지니는 것을 볼 수 있습니다.