MLE (Maximum Likelihood Estimation)
앞서 우리가 확률 분포에 대해 이야기한 이유는 딥러닝 또한 확률 분포와 밀접한 연관이 있기 때문입니다. 이번에는 딥러닝이 학습되는 원리인 최대가능도방법Maximum Likelihood Estimation, MLE에 대해서 이야기하도록 하겠습니다.
만약 우리가 대한민국 국민의 신장의 분포를 알고 싶다면 어떻게 하면 될까요? 통계청이나 병무청 등에서 이미 측정해놓은 자료를 살펴보면 되겠지만, 직접 추정해볼 수도 있을 것입니다. 그 과정은 다음의 그림과 같이 충분한 신장 샘플을 모은 후, 분포가 정규 분포를 따른다는 가정 하에 정규 분포의 평균과 표준편차를 계산할 수 있습니다. 이때 평균과 표준편차는 정규분포의 형태를 정의하는 역할을 합니다. 이처럼 확률 분포의 형태를 정의하는 값들을 분포의 파라미터라고 부릅니다.

우리는 초등학교에서 배웠기 때문에 정규분포의 평균과 표준편차를 구하는 방법을 잘 알고 있습니다. 하지만 이렇게 평균과 표준편차를 직접 계산할 수 없다면 어떻게 정규분포의 형태를 알 수 있을까요? 만약 다음과 같이 실제 분포에서 추출한 샘플들이 존재한다고 해보도록 하겠습니다.

이 샘플이 정규분포에서 추출된 것이라고 가정할 때, 정규분포의 파라미터를 알고 싶습니다. 직접 계산하는 대신 다음과 같이 주어진 샘플들에 임의의 파라미터를 적용하여 정규분포를 만들어봅니다. 만약 만들어진 정규분포가 적절하다면, 주어진 샘플들이 만들어진 분포 위에서 높은 확률을 지녀야 합니다. 따라서 이때 샘플 위의 점선들의 길이가 최대가 되었으면 합니다.
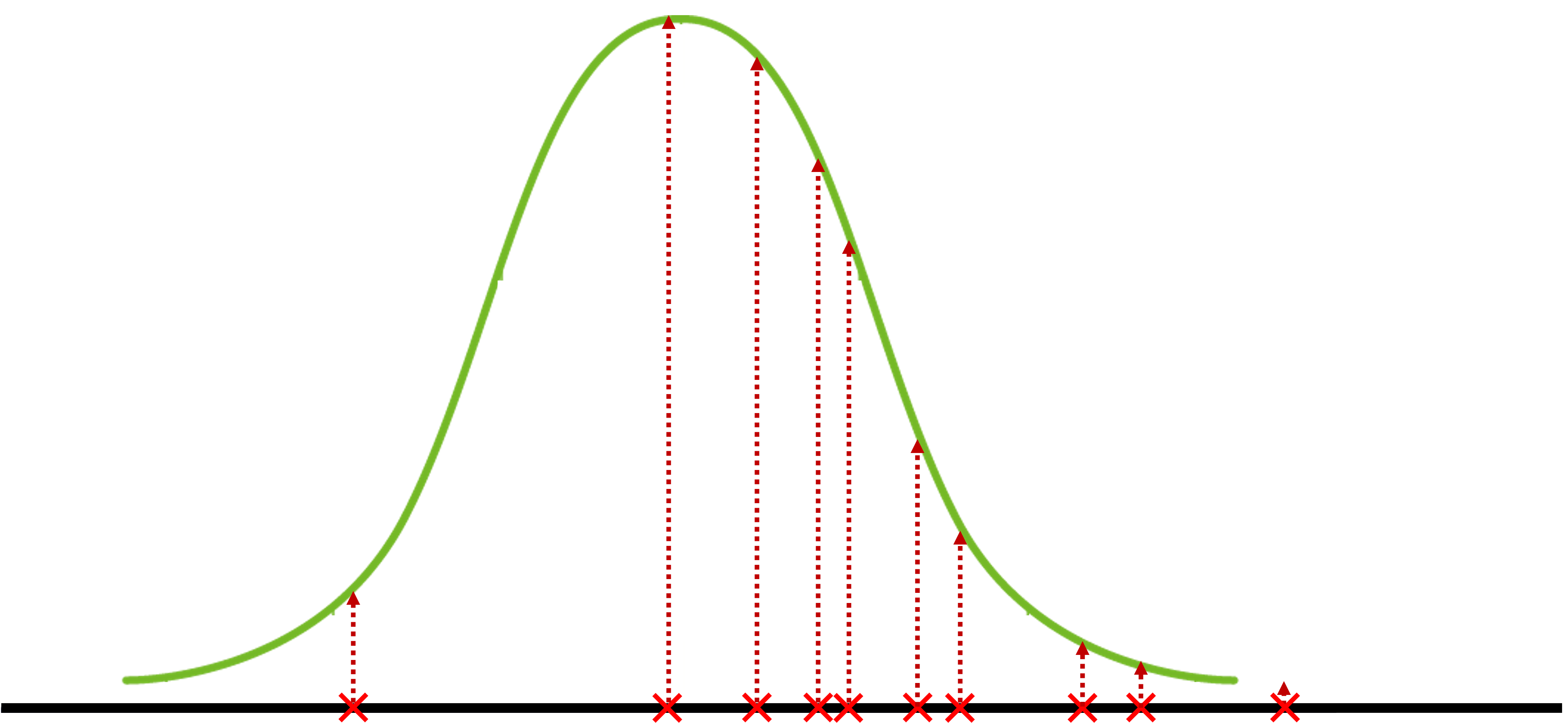
그럼 다음 임의의 파라미터를 적용하여 또 다른 분포를 만들어봅니다.
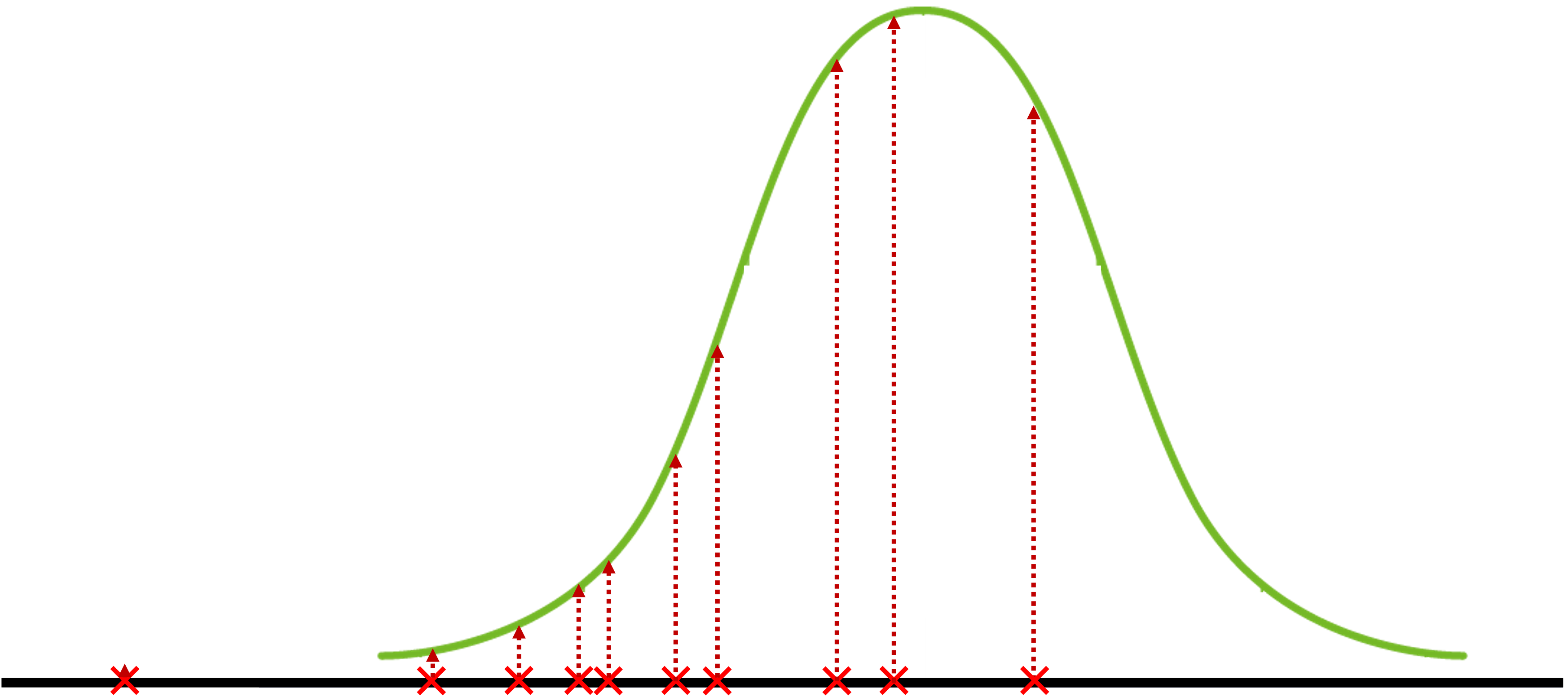
마지막으로 또 다른 임의의 파라미터를 적용하여 분포를 만들어봅니다. 그럼 앞서 만들어 본 두 정규분포보다 이 분포에 따른 점선의 길이들이 훨씬 긴 것을 볼 수 있습니다.

지금 찾아낸 파라미터의 분포가 수집한 샘플들을 잘 나타내는 최적의 분포는 아닐 수 있지만, 앞서 만들어본 3개의 분포 중에서는 가장 샘플들을 잘 나타내는 것 같습니다. 이때 이 점선 길이들의 곱을 가능도likelihood라고 합니다. 결과적으로 우리는 이 점선 길이들의 곱인 가능도를 최대로 하는 분포의 파라미터를 찾아내려던 것이라고 볼 수 있습니다. 이 과정을 최대가능도방법(MLE)이라고 부릅니다.
우리는 이러한 내용을 다음과 같이 데이터셋 $\mathcal{D}$ 가 주어졌을 때, 정규분포의 파라미터에 대한 함수로 표현할 수 있습니다. 파라미터의 변화에 따라서 가능도의 크기가 바뀔 것입니다.
\[\begin{gathered} \mathcal{D}=\{x_i\}_{i=1}^N \\ \text{Likelihood}(\mu,\sigma)=\prod_{i=1}^N{ p(x_i;\mu,\sigma) } \end{gathered}\]즉 가능도는 현재 분포의 파라미터가 수집된 데이터를 얼마나 잘 설명하는지 나타내는 점수라고 볼 수 있습니다. 그리고 가능도 함수likelihood function는 분포의 파라미터의 변화에 따라 변화하는 가능도를 나타낸 것입니다. 그럼 위의 수식을 활용하여 MLE의 또 다른 예제를 살펴보도록 하겠습니다.
만약 여러분의 친구가 도박에 빠져서 도박장에 다니는 처지가 되었다고 가정해보도록 하겠습니다. 그때 돈을 잃고 상심한 친구를 도와주기 위해서, 친구가 했던 게임에서 사용된 주사위의 분포를 추정해보도록 하겠습니다. 다음은 게임에서 나타났던 주사위의 숫자들을 나열한 것입니다.
\[\begin{gathered} \mathcal{D}=\{5, 6, 4, 6, 5, 2, 6, 1, 5, 3, 1, 6, 4, 2, 5, 6, 2, 1, 4, 5\} \end{gathered}\]그럼 우리는 이처럼 수집된 주사위 숫자들을 통해 손쉽게 주사위의 분포를 예측할 수 있습니다. 그리고 만약 수집된 샘플들의 숫자가 충분하다면 예측된 분포에 대한 신뢰도가 높을 것이고, 사기 주사위일 가능성이 높아지게 됩니다.
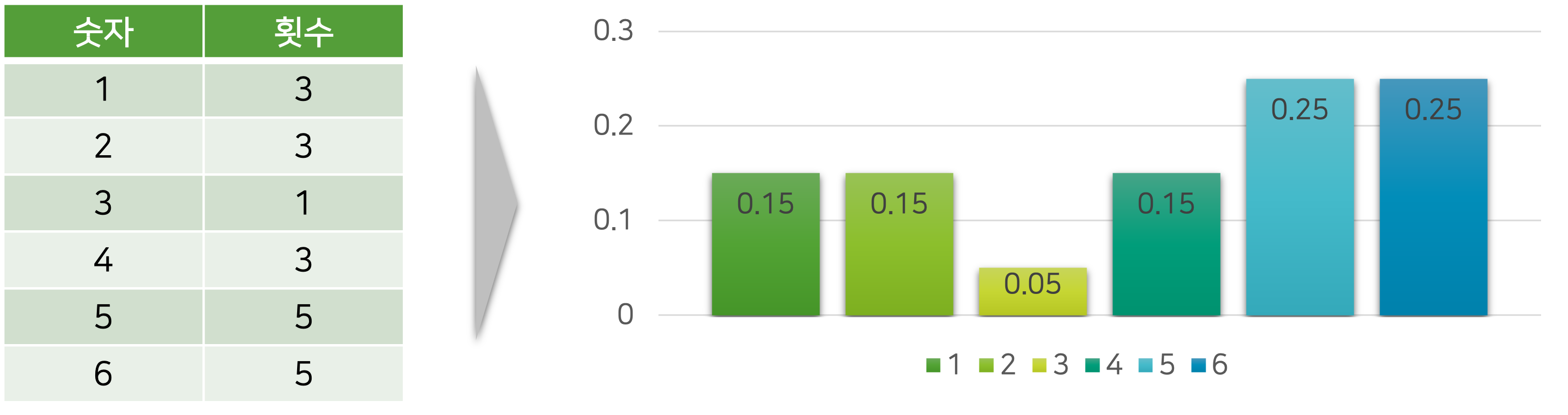
하지만 이런 방법이 없을 때, MLE를 통해서 주사위의 분포를 예측해볼 수도 있습니다. 다음과 같이 임의의 파라미터 $\theta_1, \theta_2$ 를 통해 두 개의 분포를 만들어본다고 가정하겠습니다.
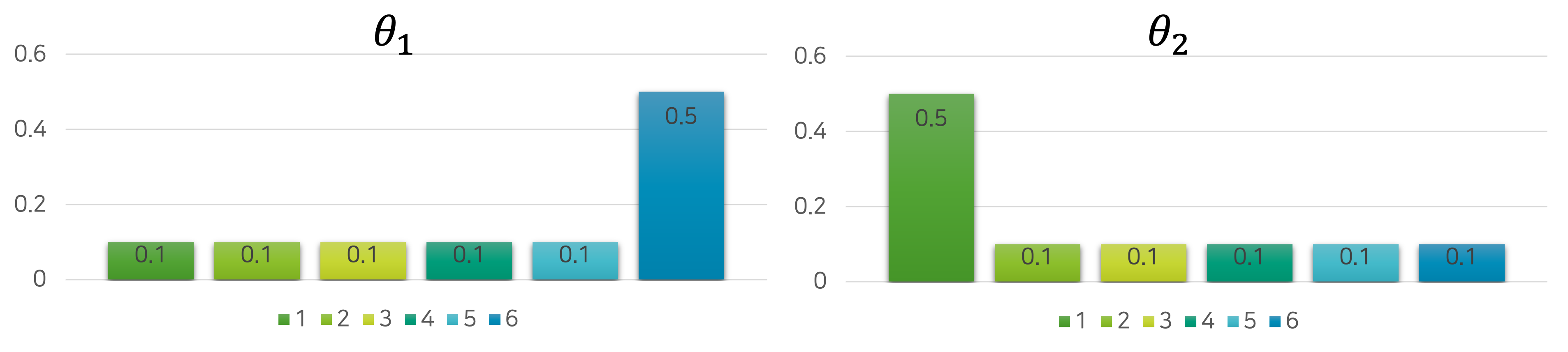
그럼 각각의 분포에 대해서 가능도를 구해볼 수 있을 것입니다.
\[\begin{aligned} \text{Likelihood}(\theta_1)&=\prod_{i=1}^{N=20}{ P_{\theta_1}(\text{x}=x_i) } \\ &=0.1^3\times0.1^3\times0.1^1\times0.1^3\times0.1^5\times0.5^5 \\ &=3.125e-17 \\ \\ \text{Likelihood}(\theta_2)&=\prod_{i=1}^{N=20}{ P_{\theta_2}(\text{x}=x_i) } \\ &=0.1^5\times0.1^3\times0.1^1\times0.1^3\times0.1^5\times0.1^5 \\ &=1.25e-18 \end{aligned}\]그럼 파라미터 $\theta_1$ 의 분포가 더 높은 가능도를 갖고 있는 것을 알 수 있으므로, 파라미터 $\theta_1$ 을 주사위의 분포로 일단 선택합니다. 그리고 곧이어 새로운 임의의 파라미터 $\theta_3$ 를 생성해서 또 다른 분포를 만들어봅니다.
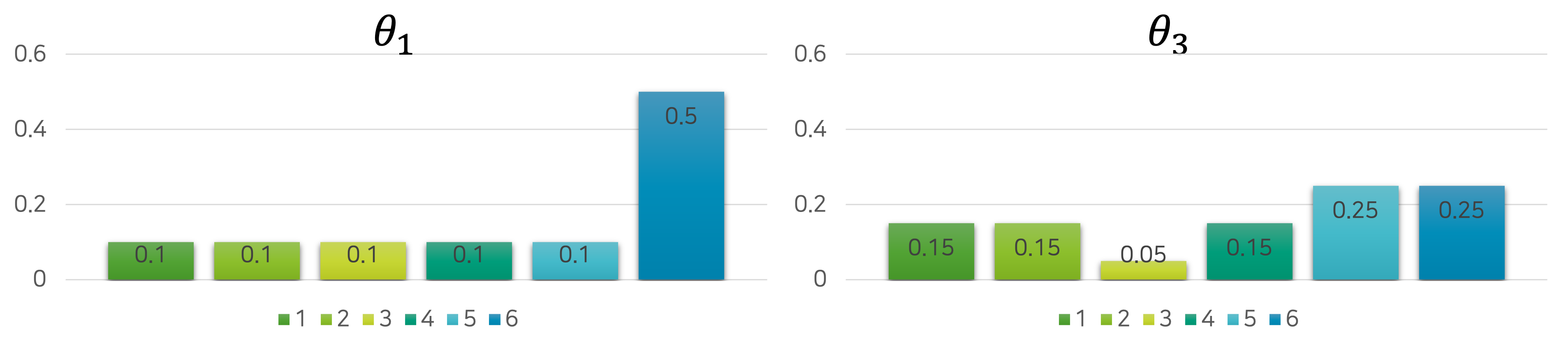
이번에는 $\theta_3$ 가 훨씬 높은 가능도를 갖는 것을 볼 수 있습니다. 이와 같은 과정을 끝없이 반복하다보면 점점 실제 주사위의 분포와 비슷한 분포를 점점 얻을 수 있게 될 것입니다. 이처럼 우리는 MLE를 통해서 실제 주사위의 분포를 추정해볼 수 있습니다.
로그 가능도
앞서 예제에서 볼 수 있듯이, 가능도는 확률의 곱으로 표현됩니다. 따라서 샘플의 숫자가 많아진다면 가능도의 크기는 굉장히 작아질 가능성이 높습니다. 그렇다면 우리는 이것을 계산할 때 언더플로underflow에 빠질 가능성이 높습니다.[1] 이때 우리는 로그를 도입하여 확률의 곱셈을 덧셈으로 바꿀 수 있습니다. (그리고 덧셈 연산이 곱셈 연산보다 빠르기도 합니다.)
\[\begin{gathered} \prod_{i=1}^N{ P_\theta(\text{x}=x_i) } \Rightarrow \sum_{i=1}^N{ \log{P_\theta(\text{x}=x_i)} } \end{gathered}\]경사상승법을 통한 MLE
앞서 우리는 MLE를 수행할 때, 임의의 파라미터를 생성해서 비교하는 작업을 반복하였습니다. 아주아주아주 운이 좋다면 파라미터를 찾아낼 수도 있겠지만, 아마도 대부분의 경우에는 최적을 파라미터를 찾기엔 굉장히 오랜 시간이 걸릴 것입니다. 이때 우리는 딥러닝에서 사용하던 경사하강법gradient descent과 같은 경사상승법gradient ascent을 활용하여 손쉽게 MLE를 수행할 수 있습니다. 경사하강법이 손실 함수loss function를 최소화하는 파라미터를 찾을 수 있게 했던 것처럼, 경사상승법을 통해 가능도 함수likelihood function를 최대화하는 파라미터를 찾을 수 있게 할 것입니다.
\[\begin{gathered} \theta\leftarrow\theta+\alpha\cdot\frac{\partial{\mathcal{L}(\theta)}}{\partial{\theta}} \end{gathered}\]예를 들어 동전을 100번 던졌을 때 27번 앞 면이 나오는 동전이 있다고 할 때, 이 동전의 파라미터를 MLE를 통해 추정해본다면 다음과 같이 진행해볼 수 있습니다. 먼저 우리는 동전을 여러번 던지는 작업은 이항분포Binomial Distribution를 따른다고 가정합니다. 그럼 이 분포의 확률질량함수probability mass function는 다음과 같습니다.
\[\begin{gathered} f(k,n,\theta)=\frac{n!}{k!(n-k)!}\times\theta^k\times(1-\theta)^{n-k} \end{gathered}\]여기서 $n=100,k=27$ 를 적용하여 가능도 함수를 그림으로 그려보면 다음과 같습니다.
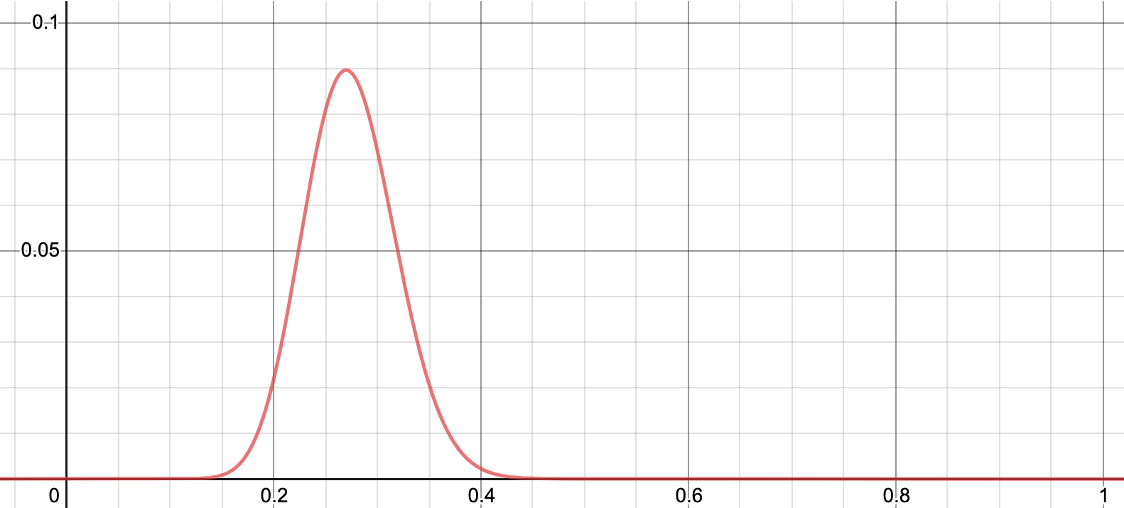
한 눈에 볼 수 있듯이, $\theta=27$ 일 때, 가능도가 가장 높은 것을 알 수 있고, 우리는 경사상승법을 통해서 이것을 쉽게 찾아낼 수 있게 될 것입니다.
[1]: https://ko.wikipedia.org/wiki/언더플로