머신러닝 프로젝트 워크플로우
이번 장에서는 머신러닝 프로젝트를 진행할 때, 업무가 진행되는 방식에 대해서 이야기하고자 합니다.
일반적인 머신러닝 프로젝트의 진행 순서
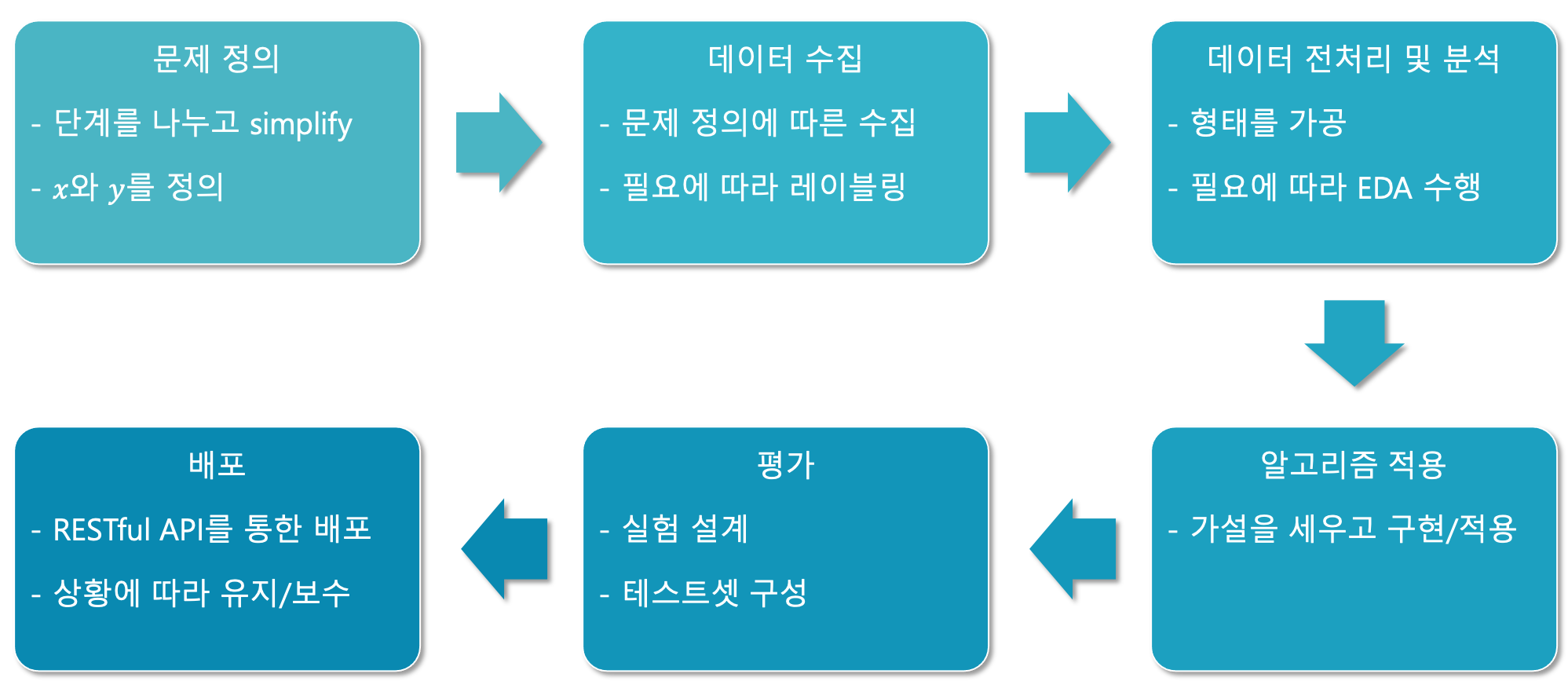
문제 정의
아마도 여기서 가장 중요한 단계가 될 것이고, 가장 어려운 단계가 될 수 있습니다. 많은 회사나 고객들이 이 단계에서 제대로 넘어가지 못하기 때문에, 프로젝트 자체가 제대로 실행되지 않거나 올바르게 수행되지 않기도 합니다. 이후에 설명할 단계들은 이 문제 정의가 올바로 이루어진 이후에야 제대로 이루어질 수 있기 때문입니다.
우리가 풀고자 하는 문제들은 대개 많은 작은 문제들이 얽혀 있기 때문에, 이것을 한번에 풀려고 하기 보단 여러 단계로 나누어서 접근하는 것이 훨씬 수월합니다. 따라서 단계를 나누고 문제를 간단하게 만들어 접근하도록 합니다.
예를 들어 인공지능 로봇에게 라면을 끓이도록 만들어야 한다고 가정해보겠습니다. 이를 위해서는 우리가 무심코 라면을 끓이는 행위를 분석해보는 것일 수도 있습니다.
- 먼저 내가 끓일 라면의 갯수를 담기에 적당한 냄비 그릇을 찾아야 합니다. 냄비의 크기가 데이터로 주어지지 않는다면 눈으로 깊이와 너비를 보고 판단해야겠네요.
- 이제 적정량의 물을 받아야 합니다. 대부분의 사람들은 경험과 감을 통해서 단순히 물의 양을 조절할 것입니다. 냄비의 너비와 깊이를 파악한 상태에서 물이 차오른 경계선의 위치를 보고 판단해도 될 것 같습니다.
- 물을 불 위에 올려놓고 끓입니다.
- 물이 끓기 시작하면 준비된 라면을 넣습니다. 이때 물의 온도를 측정할 수 있는 도구가 없다면 마찬가지로 눈으로 보글보글 끓는 물의 모양새를 보고 판단하겠죠.
- 라면이 적당히 익었는지 판단하고 요리를 중단합니다. 시간을 측정할 수도 있겠지만, 저의 경우에는 보통 라면을 젓가락으로 떠보고 시각을 통해 판단하는 것 같습니다.
이처럼 라면을 끓이는 단순한 행위도 알고보면 그 안에 복잡한 로직들로 구성되어 있는 것을 볼 수 있습니다. 그럼 이제 우리는 이 구성 로직들을 통해 우리가 만들어야 하는 함수의 역할과 입력 및 출력을 정의할 수 있습니다. 그렇게 되면 이 함수의 입출력을 위한 형태도 따라서 정의될 것입니다.
데이터 수집
이제 정의된 문제와 입출력 데이터의 형태에 따라서 데이터를 수집합니다. 이때 운이 좋다면 사내에 데이터베이스에 이미 쌓여있는 데이터를 입력 데이터 $x$로 활용할 수도 있습니다. 여기서 한발 더 나아가 데이터의 레이블label에 해당하는 출력 데이터 $y$를 동시에 구할 수도 있습니다.
예를 들어 상품에 대한 감성 분석을 수행한다고 해보겠습니다. 그럼 마침 이커머스 회사였던 덕분에 기구매 고객들의 리뷰가 쌓여있을 수도 있습니다. 여기에 또 리뷰 뿐만이 아니라, 해당 리뷰에 대응되는 5점 만점의 별점도 같이 기록되어 있는 사례도 생각해볼 수 있을 것입니다. 그럼 우리는 리뷰글을 입력으로 넣어, 별점을 예측하는 형태로 감성분석을 수행할 수 있을 것입니다.
이처럼 데이터와 레이블을 바로 얻을 수 없는 경우에는, 직접 크롤링이나 외주 등을 통해 데이터를 얻을 수 있습니다. 이와 관련하여서는 책의 다른 챕터에서 더 자세히 다루도록 하겠습니다.
데이터 전처리 및 분석
이제 수집된 데이터를 모델에 넣기 좋은 형태로 가공해주는 작업이 수행되어야 합니다. 또한 그에 앞서 데이터를 정제하는 작업이 필요합니다. 이때 수치 데이터의 경우에는 각 항목별로 분포가 상이할 수 있기 때문에, 이를 정규화normalization해주는 작업이 필요할 수 있습니다. 또한 정규화 과정에서 데이터의 성격에 따라 방법이 다르므로, 탐험적 데이터 분석EDA, Exploratory Data Analysis을 통해 데이터의 성격을 파악하는 작업도 필요합니다.
알고리즘 적용
데이터 분석을 통해 우리는 데이터의 특성을 파악하였고 나름의 가설을 세울 수 있을 것입니다. 예를 들어 데이터가 앞선 데이터 샘플의 영향을 받는 상태라고 가정한다면 시퀀셜sequential 모델링을 수행해야 할 것입니다. 이처럼 분석을 통해 가설을 세우고 이를 검증하기 위한 알고리즘 또는 신경망 아키텍처를 구성하여 학습을 수행합니다.
평가
모델의 학습이 완료되면 앞서 설정한 가설이 맞는지 올바른 평가를 통해 검증합니다. 이때, 평가가 객관적이고 공정하게 수행될 수 있도록 실험군과 대조군을 올바르게 설정하여 실험하는 것도 당연히 중요할 것입니다. 또한 평가의 난이도가 너무 쉽거나 어렵지 않도록 적절한 테스트셋을 구성하는 것도 매우 중요할 것입니다. 만약 평가를 통해 앞서 설정한 가설이 옳지 않다라고 판단되면 다시 알고리즘 적용 단계로 돌아가 가설 설정 및 알고리즘 적용을 다시 수행합니다. 또는 충분한 평가를 거쳐 만족할만한 성능이 확보되면 이제 배포의 단계로 넘어가도 좋습니다.
배포
보통 RESTful API 서버로 감싸서 배포하는 형태가 가장 권장됩니다. 요즘은 파이썬으로 구성된 라이브러리(e.g. Django, Flask)들이 많기 때문에 서로 다른 언어로 구성하는 것이 비해 파이토치와 좋은 궁합을 보여줄 수 있습니다.
사실 배포에서 더 신경써야 할 부분은 사후 유지보수 부분입니다. 사내 시스템이든 고객사의 시스템이든 이것을 운영하는 주체는 보통 다른 연구개발 주체와 다를 가능성이 높습니다. 그리고 이렇게 주체를 다르게 가져가는 것이 우리의 신상에도 훨씬 이롭습니다. 문제는 이러한 시스템들이 생각보다 유지보수가 필요한 상황들이 많이 발생할 수 있다는 것입니다. 예를 들어 음성인식이나 기계번역과 같이 입출력 데이터의 분포가 큰 변화가 없는 데이터의 경우에는 모델의 업데이트가 빈번할 필요가 없습니다. 하지만 예를 들어 제조 공장에서의 장비 이상탐지와 같은 모델의 경우에는 제조 품목(상품)이 새롭게 출시되거나 업그레이드 되는 경우에는 데이터의 값이 크게 변화할 수 있습니다. 이외에도 많은 유지보수 부분에서 이슈가 발생할 수 있습니다. 그럼 그때마다 연구개발 주체가 출동하여 이슈를 해결하는 것은 매우 괴로운 일이 될 것입니다. 따라서 최대한 시스템 운영 주체가 스스로 해결할 수 있도록 미리 시스템과 UI를 설계하고 구현하는 것도 중요한 일이 될 것입니다. 또한 이와 함계 유관 부서와 배포 이후 업무의 R&Rrole and responsibility을 잘 정의하는 것도 꼭 필요할 것입니다.