Introduction
딥러닝이란?
이 책을 본격적으로 시작하기에 앞서 딥러닝에 대해 소개하고 넘어가고자 합니다. 우리가 배우고자 하는 딥러닝이란 심층신경망Deep Neural Networks, DNN을 학습시켜 문제를 해결하는 것입니다. 이 심층신경망이라는 것은 인공신경망Artificial Neural Networks, ANN의 한 종류라고 볼 수 있을 것입니다. 좀 더 정확하게는 인공신경망을 구성하는 신경망 계층layer을 기존에 비하여 더 깊게 구성하여, 더욱 복잡한 문제를 풀 수 있도록 합니다.
어떤 이들은 인공신경망에 대해 소개할 때, 사람의 뇌 속에 있는 뉴런Neuron을 모방하여 만든 구조체라고 소개하며, 인공신경망이 마치 사람의 뇌를 모방하는 것처럼 소개하기도 합니다. 저는 굳이 그렇게 소개하지는 않겠습니다. 어쩌면 인공신경망의 시작은 사람의 뇌 구조를 모방하고자 하는 의도가 있었을지도 모르지만, 현재 딥러닝의 모델의 구조와 그 동작은 사람의 뇌를 모방하도록 의도하여 디자인 한 것들은 아닙니다. 언젠가 사람의 뇌의 동작 원리로부터 다시한번 영감을 얻어 인공지능이 한 단계 더 큰 발전을 할 수 있을지도 모르지만, 아직은 사람의 뇌와 현재 유행하는 딥러닝 방식은 그 궤를 같이하지 않습니다.
그럼 왜 딥러닝은 잘 동작하는 것일까요? 가장 큰 이유는 기존 인공신경망ANN에 비해 더 깊은 구조를 갖기 때문입니다. 과거에는 심층신경망을 학습시킬 수 없었지만, 이제 다음과 같은 이유들로 인해 쉽게 우리는 좋은 성능의 심층신경망을 얻을 수 있습니다. 첫 번째, 여러가지 수학적인 테크닉들이 가미되어 과거에는 학습시킬 수 없었던 깊은 신경망을 잘 학습시킬 수 있게 되었습니다. 두 번째, 인터넷과 모바일 기기의 발달로 빅데이터가 널리 활용되고, 이를 통해 심층 신경망을 학습시킬만한 충분한 데이터를 모아 학습시킬 수 있게 되었습니다. 마지막으로 하드웨어(GPU)의 발달로 병렬연산parallel operation에 대한 방법이 대중화되며, 신경망의 학습 및 추론 속도가 비약적으로 증가되었습니다.
왜 딥러닝인가?
깊은 구조를 갖는 것이 왜 장점이 될까요? 심층신경망의 가장 큰 특징은 비선형 함수라는 점입니다. 따라서 기존 머신러닝 방법들과 비교하여 패턴 인식 능력이 월등합니다. 결과적으로 이미지나 텍스트, 음성과 같은 다양한 분야들에서 비약적인 성능 개선을 만들 수 있었습니다. 특히, 기존 머신러닝과 달리 데이터의 특징을 일일히 설정hand-crafted feature해줄 필요가 없기 때문에, 단순히 원래raw 데이터 값을 넣어주는 것만으로도 충분히 데이터의 특징feature을 학습할 수 있습니다.
패러다임의 변화
이번에는 딥러닝으로 인해서 생겨난 기존 머신러닝과 다른 새로운 패러다임에 대해서 살펴보고자 합니다. 첫 번째, 기존 머신러닝 기반의 방식들의 특징은 여러 단계의 서브모듈sub-module로 구성되어 있다는 점입니다. 하지만 딥러닝 기반의 방식들의 최종 목표는 하나의 단일 모듈(end-to-end)로 문제를 해결하는 것입니다. 예를 들어 음성인식기의 경우, 음향모델acoustic model과 언어모델language model, 그리고 디코더decoder로 각각 구성되어 있었습니다. 그리고 이 각각의 서브모듈들을 위한 별개의 학습 데이터셋이 따로 존재하기도 합니다. 하지만 딥러닝은 하나의 모델 구조로 이를 해결하고자 합니다. 비록 모델 내에서 예전 음성인식기의 각 서브모듈에 대응하는 부분들이 있을 수 있지만, 학습 데이터가 주어졌을 때 한꺼번에 학습 가능할 것입니다. 하지만 이것은 궁극적인 최종 목표이며, 문제를 연구하는 중간 단계에서는 복잡한 문제를 작게 나누어, 각각의 작은 문제들에 대응하는 서브 모듈을 구성할 수 있습니다.
두 번째, 기존 머신러닝 방식의 경우에는 데이터의 특징feature을 손수 지정해주어야 했습니다. 연구자가 데이터를 살펴보고 특징을 파악한 후, 모델이 데이터를 인식하기 위한 숨겨진 특징이 잘 드러날 수 있도록 전처리를 잘 해주어야 했습니다. 하지만 딥러닝 모델은 복잡한 비선형 데이터에 대해서도 훌륭하게 동작하기 때문에, 데이터 내에 숨겨져 있는 특징들을 잘 파악할 수 있습니다. 따라서 기존 머신러닝 방식에서는 사람이 인식하고 지정한 특징에 대해서만 대처할 수 있었다면, 딥러닝에서는 사람이 인지할 수 있는 특징들 뿐만 아니라 미처 인지하지 못한 특징들까지도 찾아내고 인식할 수 있습니다.
그런데 이런 딥러닝의 특징은 단점을 야기하기도 합니다. 기존 머신러닝 방식의 경우에는 사람이 인지할 수 있는 특징들로 대부분 이루어져 있기 때문에, 머신러닝 모델이 동작하는 방식에 대해서 손쉽게 분석할 수 있습니다. 하지만 딥러닝 방식의 경우에는 이것을 분석하고 파악하기 어렵습니다. 예를 들어 특정 샘플이 주어졌을 때 모델이 잘못된 예측을 수행하였다면, 머신러닝 모델은 원인에 대해서 쉽게 분석할 수 있지만 딥러닝 모델은 할 수 있는 선택지가 매우 좁습니다. 이것은 생각보다 심각한 단점이 될 수도 있는데요. 우리가 딥러닝 모델을 상용화 한다면, 고객 입장에서는 제대로 동작하지 않을 때 원인에 대해서 명확하게 알고 싶어하기 때문입니다. 이에따라 이런 딥러닝의 단점을 보완하기 위한 연구(Explainable AI, XAI)도 활발하게 이어지고 있습니다.
딥러닝의 역사
딥러닝이 유행한지는 비록 십 여년 밖에 되지 않았지만, 뉴런으로부터 이어지는 인공신경망의 역사까지 합친다면 훨씬 오래된 역사를 지니고 있습니다. 딥러닝으로 인한 현재의 유행은 놀랍게도 무려 세 번째 유행입니다. 첫 번째는 1960년대에 있었던 유행입니다. 당시의 유행은 AI의 문제 난이도를 너무 과소평가한 탓에 쉽게 난관에 부딪혔고, 빠르게 불어왔던 유행만큼이나 쉽게 그 불이 꺼져버렸습니다.
1980년대, 역전파 알고리즘의 개발로 인한 중흥기
그리고 두 번째 유행은 1980년대에 시작되었습니다. 특히 제프리 힌튼Geoffrey Hinton교수에 의해서 우리가 현재 사용하는 것과 같은 역전파back-propagation 알고리즘이 제안되었고, 이것은 훨씬 더 인공신경망의 학습을 수월하게 만들어주었습니다.
하지만 고작 3~4개 계층layer를 쌓는 형태의 MLPMulti-Layer Perceptron는 복잡하고 다양한 문제들에 적용하기에는 성능이 부족했고, 대중의 관심은 차게 식어버립니다.

2000년대, 근근히 이어나가던 명맥
한때 인공지능이라는 키워드가 가끔씩 주목받기도 했지만, 대부분은 아직 기대대 크게 미치지 못하는 부족한 성능 덕분에 금방 묻혀버리고 맙니다. 다음 사진의 삼성전자 애니콜 광고도 그러한 시대적 배경을 잘 보여줍니다. 무려 TV에서 인공지능 음성인식 기능을 핸드폰의 메인 기능으로 소개하며 광고하였지만, 당연히 성능은 크게 부족하였고 금방 외면받고 말았습니다.

이때 두 번째 유행 이후의 빙하기가 어찌나 매서웠던지, 1980년대의 찬란했던 연구들의 명맥조차 끊어지는 현상들이 발생하였는데요. 어찌나 심하게 빙하기가 왔던지, 1980년대 연구했던 내용을 학계가 잘 기억하지 못할 정도였습니다. 하지만 그런 와중에도 인공지능에 대한 미련을 놓지 못하고, 근근히 인공지능에 대한 연구들이 계속되고 있었습니다.[1] 힌튼 교수에 의해서 RBMRestricted Boltzmann Machine이나 DBNDeep Belief Networks을 활용한 연구가 진행되기도 하고, 요슈아 벤지오Yoshua Bengio 교수의 지도하에 Stacked Denoising Autoencoder 등의 방법이 제안되기도 하였습니다.
[1]: 그리고 그들은 이번 세 번째 유행에서 대가들이 되었습니다.
2010년대 초, ImageNet 우승과 음성인식의 상용화
그러던 와중에 2012년, 심층신경망에 의해 컴퓨터 비전computer vision 분야에서 이른바 대박이 터지게 됩니다. 컴퓨터 비전 분야의 권위있는 대회인 이미지넷ImageNet에서, 기존의 우승자들과 달리 심층신경망을 활용한 방법이 우승을 차지하게 됩니다. 이 사건으로 인해 딥러닝이라는 방법론은 단숨에 세간의 주목을 받게 되고, 곧이어 이어지는 이미지넷 대회에서도 모두 딥러닝을 활용한 방법들이 우승하며 유행이 시작됩니다.
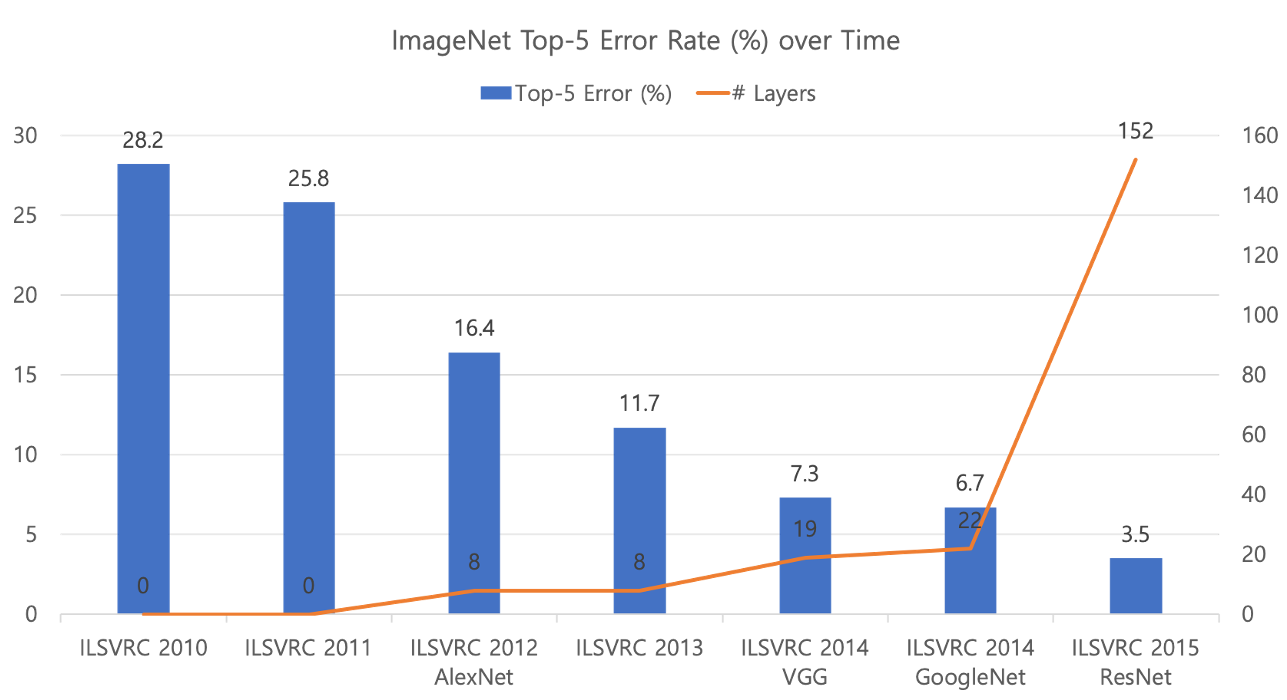
앞의 그림에서 볼 수 있듯이, 2012년도에 8개의 계층으로 시작된 심층신경망을 시작으로, 그 갯수가 점점 늘어나서 나중에 2015년의 ResNet은 무려 150개가 넘는 계층을 사용한 것을 볼 수 있습니다. 또한 2012년에 딥러닝의 활용으로 크게 줄어든 Top-5 오류는 계속해서 줄어드는 것을 확인할 수 있습니다.
그리고 사실 널리 알려지지 않았지만, 이미지 분야에서의 딥러닝의 활약에 앞서, 음성인식 분야에서도 딥러닝이 야금야금 그 정복지를 넓히고 있었습니다. 구글에서는 2011년 음성인식에 심층신경망을 도입하여 성능을 획기적으로 끌어올렸습니다. 사실 기존의 음성인식은 굉장히 복잡하고 다양한 서브모듈sub-module들로 구성되어 있었습니다. 여기서 발음을 인식하는 일부 모듈을 심층신경망으로 대체하여 성능을 개선하였습니다.
2015년, 기계번역의 상용화
사실 자연어처리 분야는 다른 분야들에 비해서 딥러닝의 유행에 편승하지 못하고 있었습니다. 딱히 큰 발전이랄 것은 없었고, 기껏해야 단어를 임베딩 벡터로 변환하거나, 텍스트를 특정 클래스로 분류하는 작업에 딥러닝을 활용할 뿐이었습니다. 필자도 이런 현상을 두고, 혹시나 앞서 두 번의 유행과 비슷한 양상으로 흘러가지는 않을지, 딥러닝에 대해 의심어린 시선을 거두지 못하고 있었습니다. 왜냐하면 다른 동물이나 곤충들도 소리를 듣고 구분하고 사물을 보고 구분할 수 있기 때문에, 언어 문제에 대한 해결이야말로 인간에 필적하는 지능으로 다가가는 길이라고 생각했기 때문입니다.
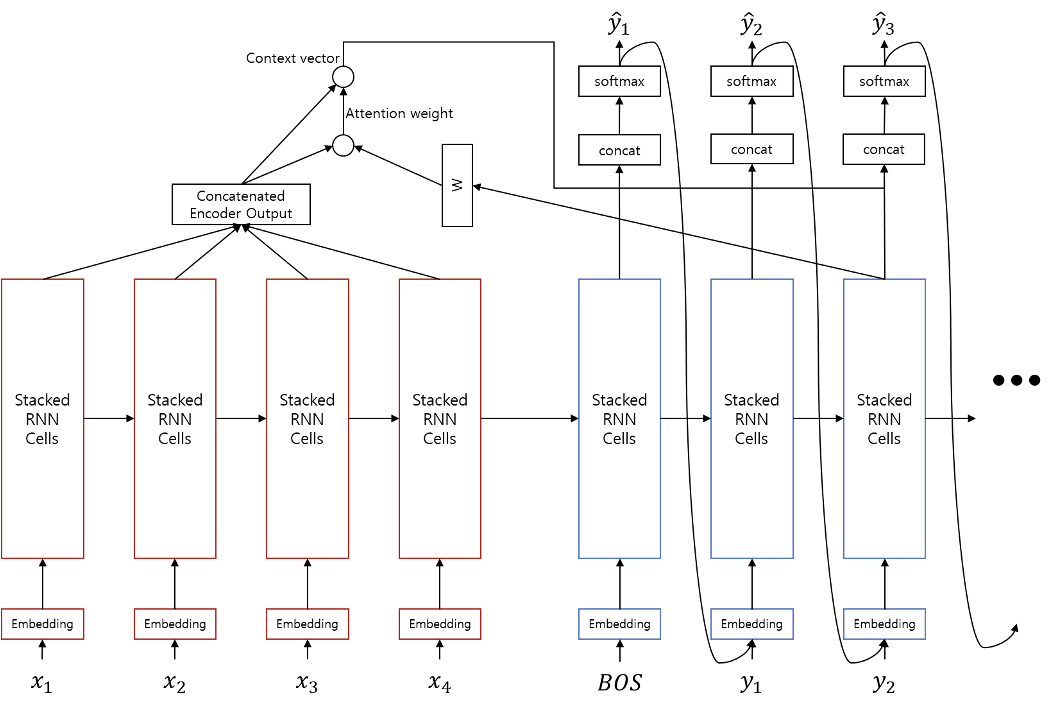
하지만 2015년 시퀀스투시퀀스Sequence-to-Sequence와 어텐션Attention 방법이 제안됨에 따라, 자연어처리의 꽃이라고 할 수 있는 기계번역machine translation이 정복되는 것을 보며, 딥러닝에 대한 의심은 사라지게 되었습니다. 이제 시퀀스투시퀀스에 의해서 더이상 자연어처리는 단순히 텍스트를 숫자로 변환하는 것에 그치지 않고, 숫자를 텍스트로 변환할 수 있게 됩니다. 즉, 자연어생성natural language generation의 시대가 열리게 되었고, 딥러닝을 활용한 자연어처리 연구는 폭발적으로 늘어나게 됩니다.
2016년, 알파고의 승리

2016년 3월 벌어진 딥마인드 알파고와 이세돌의 바둑 대결을 모르는 독자분들은 없을 것입니다. 이 사건으로 인해 특히 대한민국에는 인공지능 열풍이 불게 되었으며, 강화학습에 대한 관심도도 높아지게 되었습니다. 더불어 바둑계에도 한차례 혁명이 몰아쳤다고 합니다. 실제로 딥러닝에 대해 모르는 분들일지라도 알파고라는 단어는 알 만큼, 알파고가 인공지능 산업에 미친 영향은 굉장히 지대합니다.
2017년 트랜스포머의 등장
자연어처리 분야에서 2016년과 2017년은 기계번역이 완성되는 해였습니다. 비록 가장 나중에 딥러닝의 영향을 받은 딥러닝 분야였지만, 가장 먼저 end-to-end 딥러닝 방식만으로 기계번역 상용화를 달성하였고, 딥러닝 이전의 성능과 대비하여 천지개벽 수준의 압도적인 차이를 보여주게 됩니다. 한때는 자연어처리의 꽃이라고 불리웠던 기계번역이었고 가장 많은 연구가 이루어졌던 분야였지만, 이 시점을 계기로 자연어처리 연구는 더이상 학계의 주류가 아니게 됩니다.
![]()
이러한 사건이 발생하는데 큰 공헌을 한 아키텍처가 바로 트랜스포머Transformer입니다. 앞의 그림은 트랜스포머의 구조를 도식화 한 것입니다. 트랜스포머는 “Attention is All You Need”라는 제목의 논문을 통해 제안되었는데요. 제목에서 알 수 있듯이, 어텐션attention만을 활용하여 기존의 시퀀스투시퀀스를 대체하였고, 자연어처리에서 매우 큰 성능의 향상을 불러왔습니다.
이 트랜스포머는 현재의 딥러닝에서 굉장히 큰 지분을 차지하고 있습니다. 처음에는 자연어처리 또는 시퀜셜sequential 데이터에 대한 모델링을 위해 제안된 구조이지만, 지금은 컴퓨터 비전과 음성인식 등 딥러닝이 사용되는 대부분의 분야에 사용되고 있습니다. 따라서 최신 딥러닝 트렌드를 이해하기 위해서는 어텐션 알고리즘과 트랜스포머 아키텍처에 대한 올바른 이해가 중요합니다.
2018년, GAN을 통한 이미지 합성의 발전과 대형 언어모델의 등장
GANGenerative Adversarial Networks이라는 방법은 2014년에 최초로 제안된 이미지 생성 방법입니다. 두 개의 서로 다른 네트워크가 서로 경쟁하며 한 쪽은 이미지를 합성한 것을 들키지 말아야 하고, 다른 한 쪽은 합성한 이미지를 찾아낼 수 있도록 학습합니다. 이에 따라 서로 경쟁하며 발전하면, 결국에는 사실 같은 합성(생성)된 이미지를 만들어낼 수 있다는 이론입니다.

앞의 사진들에서 나오는 얼굴들은 모두 실존하는 인물들이 아닙니다. GAN을 활용하여 합성해낸 얼굴 사진입니다. 앞의 사진에서 볼 수 있듯이, 처음에는 사람의 얼굴을 합성하더라도 해상도가 낮으며 어색함이 많았습니다. 하지만 점점 시간이 지남에 따라 사람이 구별하기 힘들 정도로 정교한 얼굴 사진을 만들어내며, 이미지 생성의 기술도 점차 완성되어가고 있습니다. 이처럼 컴퓨터 비전 분야에서는 이미지 생성에 큰 바람이 불고 있었던 반면에, 자연어처리 분야에서는 또 다른 혁명이 시작되고 있었습니다.
트랜스포머 아키텍처의 등장 이후로 이를 활용한 많은 연구들이 이어졌습니다. 이 중에 하나가 바로 대형large scale 사전학습 언어모델pretrained language model, PLM입니다. 인터넷 상에 존재하는 수많은 문장 데이터(코퍼스corpus)를 모아서 단순히 다음 단어 또는 빈 칸의 단어를 예측하도록 사전 학습시킨 후, 다양한 하위 작업downstream task들에 파인튜닝fine-tuning하도록 하여 성능을 높이는 방법입니다. 따라서 더 적은 양의 데이터로도 더 높은 성능을 거둘 수 있게 되었습니다.
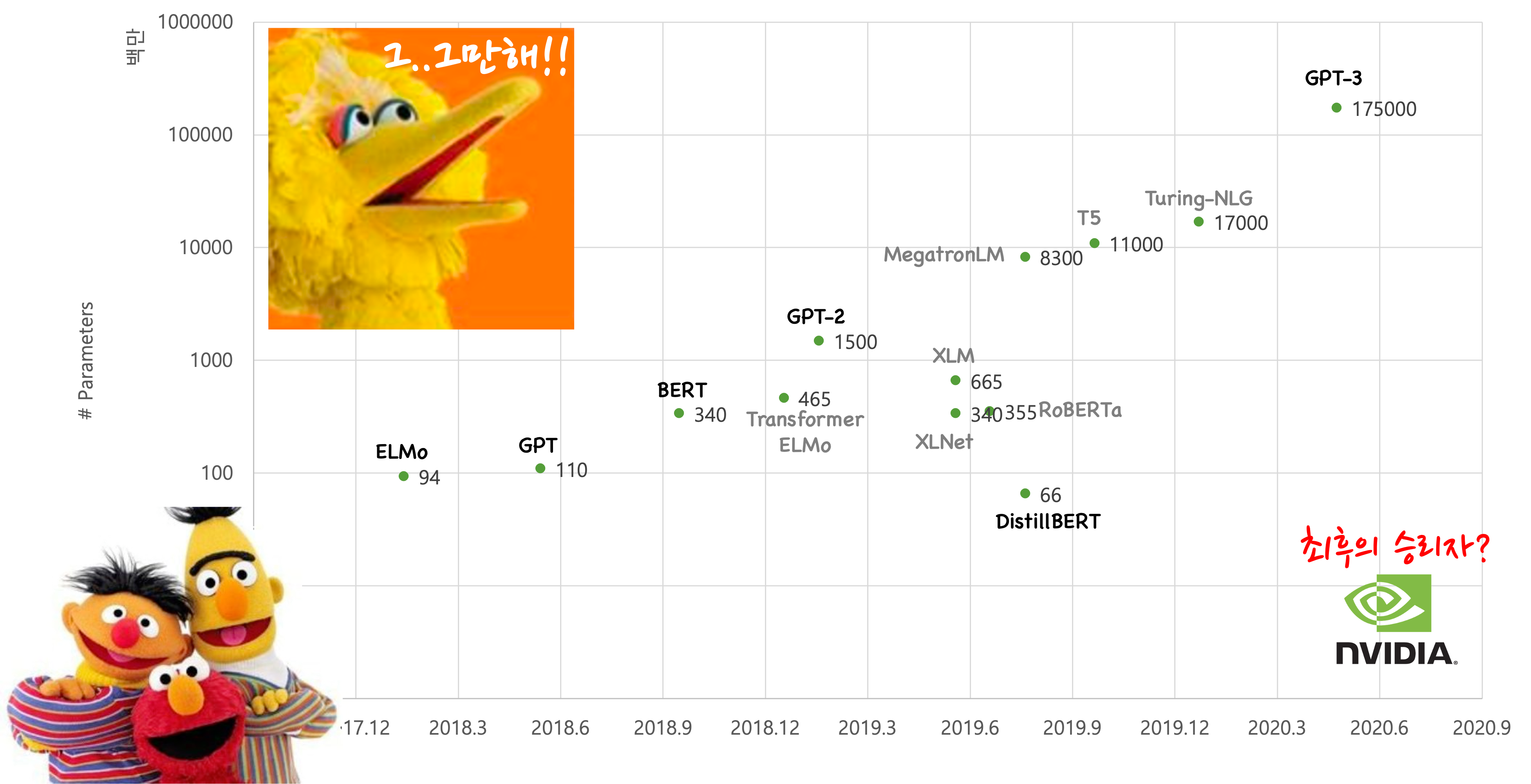
이와 같은 대형 사전학습 언어모델의 성공은 이후 점점 모델의 크기를 키워가는 방향으로 경쟁을 촉발시킵니다. 앞의 도표에서 볼 수 있듯이, GPT와 BERT의 성공으로 시작된 모델 크기 경쟁은 추후 GPT-3에 이르러 무려 175B이라는 어마어마한 크기의 모델을 탄생시키기에 이릅니다. 하지만 대형 신경망을 구축하고 학습해야 하기 때문에, 사전 학습 데이터와 GPU, 전력이 굉장히 많이 필요합니다.[2] 결국 작은 규모의 실험실이나 회사에서는 이와 같은 연구를 진행하기 어렵다는 이야기가 되기도 하며, 연구개발 자금력에 의한 연구의 양극화가 발생하고 있습니다. 실제로 이와 같은 대형 언어모델들에 대한 연구는 구글이나 오픈에이아이Open AI와 같은 큰 기업들에 의해서 주도되고 있습니다.
[2]: 이와 같은 큰 모델을 학습하기 위해서는 많은 전력이 필요하고, 이에 따른 탄소배출과 환경 파괴에 대한 경각심도 높아지고 있습니다.
2020년, GPT-3의 등장
앞서 언급했던대로 대형 사전학습 언어모델의 성공은 모델의 거대화에 대한 경쟁을 유발시켰습니다. 대기업들의 앞다투어 더 큰 언어모델을 학습시켜 성능을 자랑하게 되었습니다. 그러던 2020년, 오픈에이아이Open AI에서는 GPT-3라는 매우 거대한 모델을 발표하게 되었습니다.

이 GPT-3는 기존의 GPT 시리즈와 방법면에서는 큰 차이가 없었지만, 크기를 키워 더 많은 일을 해낼 수 있었습니다. 특히 일반화 능력이 매우 뛰어나서, 매우 적은 수의 텍스트 샘플을 보고도 마치 사람과 같이 훌륭한 추론을 해낼 수 있습니다. 이러한 추론 능력은 너무 인상적이고 뛰어나기 때문에, 큰 모델을 만들면 뭐든지 해낼 수 있을 것만 같은 생각이 들 정도입니다. GPT-3의 성공 이후, 모델의 거대화는 기존의 라지스케일large scale을 넘어, 하이퍼스케일hyper scale로 넘어가고 있습니다. 필자도 이 책을 출판하는 시점에서는 GPT-3를 학습시키고 이를 활용한 대화 모델링을 연구개발 하고 있습니다.
열린 문화와 빠른 트렌드 변화
보시다시피 딥러닝은 너무나도 빠른 속도로 발전해왔습니다. 너무 발전 속도가 빠른 나머지, 한달만에 최첨단State of the Art, SOTA성능이 갈아치워지는 등, 따라가기도 벅찰 정도입니다. 이와 같은 혁명과 같은 딥러닝의 발전이 가능했던 큰 원동력이 무엇이었을까요?

필자는 바로 열린 문화라고 생각합니다. 연구 성과가 바로 공개되고 이를 재현할 수 있는 코드가 공유되는 문화가 있었기 때문에, 딥러닝이 이처럼 빠른 속도로 발전할 수 있었다고 생각합니다. 원래도 컴퓨터 공학 분야는 저널journal에 비해서 학술대회conference가 좀 더 활발하게 활용되고 있었습니다. 학술대회의 특징은 훨씬 더 빠른 논문 심사라고 볼 수 있을텐데요. 이로 인해서 다른 분야에 비해 발전이 빠른 컴퓨터 공학 분야는 좀 더 연구 성과를 빠르게 공개할 수 있었습니다. 하지만 이러한 컨퍼런스조차 연구의 속도를 따라오지 못하게 되자, 아카이브ArXiv라는 웹사이트를 적극적으로 활용하기 시작하였습니다. 그리고 이 웹사이트는 동교 검토peer review 과정을 생략할 수 있게 되어 훨씬 더 빠른 연구 성과 공유가 가능하게 되었습니다. 게다가 논문을 공유할 때, 연구 성과를 재현할 수 있는 소스코드를 공개하는 것이 권장되면서, 다른 연구자들의 연구 내용을 더 쉽게 이해하고 검증할 수 있게 되고, 이를 바탕으로 더 빠르게 새로운 연구 성과를 거둘 수 있게 되었습니다.
부작용: 사용자의 부담 증가
하지만 이런 훌륭한 열린 문화에도 단점이 뒤따릅니다. 바로 동료 검토의 부재로 인한 정보의 홍수입니다. 대부분의 논문들은 자신의 연구 성과를 최고라고 포장합니다. 하지만 대부분의 논문들은 대중들에게 주목받지 못한 채 뒤안길로 사라지는 것이 현실입니다. 그럼 이런 논문들 중에서 옥석을 가리는 일이 기존에는 동료 검토였지만, 이제는 동료 검토가 사라진 시점에서는 자신의 시야를 믿을 수 밖에 없습니다.[3]
또한 깃허브에 공개되어 있는 코드들도 곧바로 믿을 수 없습니다. 해당 논문의 저자가 직접 공개한 코드가 아니라, 제3자가 구현하고 공유한 코드라면 구현 내용에 어떤 잘못이 있는지 확인이 필요합니다. 행여나 잘못된 구현을 확인하지 못한 채, 자신의 프로젝트에 적용시켰다가 한참 시간이 지난 후에 이것을 발견한다면 큰 낭패가 될 것입니다. 결과적으로 이를 종합해 보면 열린 문화는 딥러닝의 빠른 발전 속도에 큰 기여를 하였지만, 그 과정에서 각각의 개인들은 좋은 연구와 나쁜 연구를 가릴 수 있는 시야를 가질 수 있도록 노력해야 할 것입니다. 그렇지 않으면 쏟아져나오는 연구 결과들 속에서 이리저리 헤매게 될 것입니다.
[3]: 다행히도 트위터나 페이스북의 딥러닝 커뮤니티에 가끔씩 좋은 논문들이 공유되기도 합니다.