AI-Hub 공개 데이터셋을 활용한 한/영 기계번역
이번 포스팅은 AI-Hub에서 공개한 160만 문장쌍의 한국어-영어 문장쌍 코퍼스를 활용한 한/영 기계번역기를 만드는 과정을 공유하고자 합니다. 활용한 전처리 방식에 대해 소개 및 공유하고, Sequence-to-Sequence[1, 2]와 Transformer[3]에 대해서 소개하고 기계번역 학습 결과 성능을 공유하고자 합니다. 또한 강화학습을 활용한 MRT[4]와 Dual Learning에 기반한 DSL[5]을 소개하고, 이를 각 모델에 도입한 결과도 공유하고자 합니다.
이 포스팅의 모든 내용은 패스트캠퍼스의 온라인 자연어생성 강의에 수록되어 있습니다. 해당 강의는 자연어처리 초급 강의에 이어 자연어생성(NLG)를 주로 다루고 있습니다. 특히 아래에서 소개할 기계번역의 사례를 통해, 자연어 생성의 이론과 실습을 총 30시간 이상에 걸쳐 이야기합니다. 해당 강의 또는 이 포스팅과 같은 방법을 통해 우리는 준수한 성능의 기계번역기를 혼자서 개발할 수 있습니다. – 아래의 성능 단락을 참고 바랍니다. 만약 사용자가 적절한 크롤링을 통해 얻은 코퍼스까지 추가한다면 더욱 좋은 기계번역기를 만들 수 있을 것입니다.
깃 저장소(Simple NMT)에 전체 코드가 공개되어 있으니, 필요에 따라 참고하시기 바랍니다. Simple NMT는 Sequence-to-Sequence와 Transformer를 기본 모델로 제공하며, MLE 방식의 학습 이외에도 강화학습을 활용한 MRT 방식, 그리고 Dual Supervised Learning 방식을 통해 학습할 수 있는 코드를 제공합니다. 또한, Beam-search를 지원하여 일반적인 추론방식 대비 더 높은 성능을 얻을 수 있게 합니다.
Preprocessing
Cleaning
다행히 AI-Hub의 데이터들은 이미 잘 정제되어 있는 상태이므로, 굳이 별도의 정제 과정을 거칠 필요가 없습니다. 만약 웹크롤링 또는 영화/드라마 자막을 코퍼스로 삼고자 한다면, 번역에 알맞은 형태로 노이즈를 제거하거나, timestamp를 맞추는 작업 등을 수행해줘야 할 것입니다.
Tokenization
한국어는 말이 길어질 것 같으니, 먼저 영어의 분절(tokenization)에 대해서 먼저 소개합니다.
영어는 굴절어의 성격을 띄는 고립어에 속합니다. (라틴어가 굴절어에 속하지만, 세월이 지나면서 영어는 고립어에 속하게 되었습니다.) 영어의 경우에는 띄어쓰기가 도입된 역사가 훨씬 오래됐기 때문에, 언어 자체가 띄어쓰기와 궁합이 매우 좋습니다. 따라서 띄어쓰기를 따로 교정해줘야 할 필요성은 거의 없습니다. 다만 서로 다른 타입의 캐릭터(character)들 사이에 공백(white-space)을 넣어주는 작업은 필요합니다. 이 작업은 MosesTokenizer를 통해 수행할 수 있습니다.
영어와 달리, 한국어는 교착어에 속합니다. 교착어는 어간에 접사가 붙어 문장 내에서 해당 단어의 의미와 역할이 정해지게 됩니다. 따라서 우리는 하나의 어간에 다양한 접사가 붙을 수 있기 때문에, 단순히 공백을 delimiter로 삼는다면 너무 큰 어휘사전(vocabulary)을 갖게 될 것입니다. 따라서 어간과 접사를 분리함으로써, 어휘사전의 단어 수를 줄이고 단어에 대한 희소성을 감소시킬 수 있습니다.
더욱이 한국어의 경우에는 근대에 띄어쓰기가 도입되었기 때문에, 아직 띄어쓰기와 궁합이 좋지 않습니다. – 여전히 중국어와 일본어에는 띄어쓰기가 존재하지 않습니다. 따라서 우리는 띄어쓰기가 불분명하더라도 의사소통을 하는데 전혀 무리가 없으며, 결과적으로 띄어쓰기가 잘 지켜지지 않는 원인이 됩니다. 즉, 우리가 수집한 데이터셋은 띄어쓰기가 중구난방일 수 있으며, 웹크롤링 등을 통해 수집한 문장이 많을수록 훨씬 더 중구난방이 될 것입니다. 그러므로 우리는 분절(tokenization)을 통해 코퍼스의 띄어쓰기를 정제(normalization)할 수 있습니다.
최신 유행을 따른다면 뒷 단락에서 소개할 서브워드 분절(Subword Segmentation)은 필수적인 요소로 자리잡고 있는데, 이러한 한국어의 언어적 특징을 무시한 채 곧바로 서브워드 분절을 적용한다면, 중구난방 띄어쓰기로 인해 서브워드 분절이 이상적으로 이루어지지 않을 것입니다.
Split into Train/Valid/Test set
이제 이렇게 일차로 분절된 코퍼스를 정해진 비율에 따라 학습/검증/테스트의 3가지 데이터셋으로 분리합니다. AI-Hub에서는 160만 문장쌍으로 이루어진 코퍼스를 제공합니다. 만약 테스트셋을 별도로 마련하지 않고 임의로 구성한다면 아래와 같은 비율도 괜찮은 선택이 될 수 있습니다.
| 데이터셋 | #Lines |
|---|---|
| 학습 | 140만 |
| 검증 | 19.9만 |
| 테스트 | 0.1만 |
아쉽게도 저는 처음에 “아무 생각 없이” 일괄적으로 “120만/20만/20만”의 구성을 하는 바람에 학습 데이터가 위의 제안보다 적게 들어갔습니다. 어떻게 보면 위의 구성보다 더 나은 비율 구성 같지만, 20만 문장의 테스트셋은 빔써치(beam-search)와 BLEU측정에서 너무 많은 시간이 소요되어 실제 테스트셋으로 활용하는 것은 사실상 불가능합니다. 따라서 제안된 위의 구성에서 테스트셋이 너무 작은 것이 흠이지만, 어차피 따로 성의있게 잘 구성된 테스트셋이 아니므로 적당히 모델 사이의 성능을 비교하기 위한 용도로 사용하고자 합니다.
Subword Segmentation (Byte Pair Encoding, BPE)
Rich Sennrich 교수에 의해 처음 제안된 서브워드 분절(Subword Segmentation)[6]은 압축 알고리즘인 BPE 알고리즘을 활용합니다. 이제 이 알고리즘은 자연어처리 분야에서 거의 기본이 되었는데요. 중요한 점은 학습셋(training set)을 기준으로 BPE 모델이 학습되어야 한다는 것입니다. 이것도 데이터에 기반하여 통계를 작성하고 이를 바탕으로 분절을 수행하는 것이기 때문에, 학습 데이터만을 보고 분절이 수행되어야 추후에 분절 여부에 따른 정확한 성능을 측정할 수 있습니다.
본래 영어의 경우에도 라틴어의 영향을 받았기 때문에, 각기 다른 의미를 지닌 subword들이 모여 하나의 단어를 이룹니다. 한글의 경우에도 원래 한자의 영향을 받았기 때문에, 각 캐릭터가 의미를 지니고 이것들이 모여 하나의 전체 의미를 지닌 단어를 만들어냅니다.
| 언어 | 서브워드 | 단어 |
|---|---|---|
| 영어 | Con(together) + centr(center) + ate(make) | Concentrate |
| 한글 | 집(모을 집) + 중(가운데 중) | 집중 |
이런 언어의 특성을 반영하여 각 언어별로 별도의 알고리즘을 적용하여 서브워드 분절기를 만드는 대신, BPE 알고리즘을 활용하여 데이터에 기반하여 서브워드 분절을 수행합니다. 다만, 앞선 단락에서 이야기 한 것처럼, 한국어의 경우에는 띄어쓰기가 워낙 중구난방이므로 Mecab을 활용한 분절 이후에 서브워드 분절을 추가로 적용합니다. (Mecab을 활용한 분절은 생략하여도 괜찮습니다.)
Detokenization
텍스트 분류와 같은 task와 달리, 기계번역과 같은 NLG task들은 생성된 문장을 사람이 읽고 이해할 수 있는 형태여야 합니다. 따라서 신경망에 입력되기 좋은 형태로 분절된 생성 문장들을 다시 사람이 읽기 좋은 형태로 만들어주는 작업이 필요합니다. 이러한 작업을 detokenization이라고 부르며, 이는 분절을 수행할 때 약간의 트릭을 추가함으로써 쉽게 해결될 수 있습니다.
- 영어 원문
There's currently over a thousand TED Talks on the TED website. - tokenization을 수행하고, 기존 띄어쓰기와 구분을 위해 ▁ (U+2581) 삽입
▁There 's ▁currently ▁over ▁a ▁thousand ▁TED ▁Talks ▁on ▁the ▁TED ▁website . - subword segmentation을 수행, 공백 구분 위한 ▁ 삽입
▁▁There ▁'s ▁▁currently ▁▁over ▁▁a ▁▁thous and ▁▁TED ▁▁T al ks ▁▁on ▁▁the ▁▁TED ▁▁we b site ▁. - whitespace를 제거
▁▁There▁'s▁▁currently▁▁over▁▁a▁▁thousand▁▁TED▁▁Talks▁▁on▁▁the▁▁TED▁▁website▁. - ▁▁을 white space로 치환
There▁'s currently over a thousand TED Talks on the TED website▁. - ▁를 제거
There's currently over a thousand TED Talks on the TED website.
모델 학습
Simple NMT는 Sequence-to-Sequence 모델과 Transformer 모델을 제공합니다. 또한, 강화학습을 활용한 MRT 방식, Dual Supervised Learning (DSL) 방식을 통해 해당 모델들을 학습할 수 있도록 합니다.
학습 환경
저의 경우에는 MRT와 DSL에서의 적절한 hyper-parameter를 찾기 위해 힘든 과정을 거쳤는데요. 특히, 기계번역의 경우에는 학습의 결과가 1~2일은 소요되기 때문에, 빠르게 결과를 보고 튜닝할 수 없어 어려움이 많았습니다. 처음에는 1080Ti 한 대를 가지고 학습을 진행하다가, 더딘 진행속도에 결국 2080Ti를 2대 더 구입하여 학습을 진행하였습니다. 그 결과 PyTorch에서 제공하는 AMP(Automatic Mixed Precision)[7] 기능의 효과를 체감할 수 있었는데요. 1080Ti의 경우에는 메모리 사용량 개선 뿐, AMP로 인한 속도 개선은 없었던 것에 반해, 2080Ti의 경우에는 메모리 사용량 개선 뿐만 아니라, 속도 개선까지 확인할 수 있었습니다. 결과적으로 2080Ti의 경우에는 같은 조건일 때의 1080Ti에 비해서 2배 이상의 속도 개선이 이루어질 수 있었습니다. 최종적으로는 1대의 1080Ti와 2대의 2080Ti를 갖고 학습을 진행하였습니다.
Sequence-to-Sequence with Attention
Sequence-to-Sequence(Seq2seq)는 이전까지 별다른 연구가 진행되지 못하던 NLP 학계에 큰 파란을 일으키며, NLG의 시대를 연 장본인입니다. 특히, Attention과 함께 시너지를 내며, 순식간에 기계번역을 정복하였습니다. Seq2seq는 크게 3가지 서브모듈로 이루어져 있습니다.
첫 번째로는 인코더입니다. 인코더는 입력 문장을 처음부터 끝까지 받아, bi-directional LSTM을 통해 문장을 하나의 벡터로 압축변환 합니다. 그리고 디코더는 인코더로부터 해당 벡터를 넘겨받아 디코딩을 시작합니다. 디코딩 작업은 <BOS>라는 special token이 첫 번째 입력으로 들어오면 다음 단어를 예측하기위한 출력(hidden state)을 반환합니다. 마지막으로 제너레이터는 이 hidden state를 입력으로 받아 softmax layer를 거쳐 각 단어별 확률 값을 반환합니다.
이를 아래와 같이 Maximum Likelihood Estimation (MLE)를 통해 학습을 진행하게 됩니다.
\[\begin{gathered} \mathcal{D}=\{(x_i, y_i)\}_{i=1}^N \\ \text{where }x_i=\{x_{i,1},\cdots,x_{i,n}\}\text{ and }y_i=\{\text{<BOS>},y_{i,1},\cdots,y_{i,m},\text{<EOS>}\}. \\ \\ \begin{aligned} \mathcal{L}(\theta)&=-\frac{1}{N}\sum_{i=1}^N{ \log{P(y_i|x_i;\theta)} } \\ &=-\frac{1}{N}\sum_{i=1}^N{ \sum_{t=1}^{m+1}{ \log{P(y_{i,t}|x_i,y_{i,<t};\theta)} } } \end{aligned} \\ \\ \hat{\theta}=\underset{\theta\in\Theta}{\text{argmin }}{\mathcal{L}(\theta)} \end{gathered}\]Transformer
Transformer는 현재 자연어처리의 모든것이라고 해도 과언이 아닙니다. 2017년 처음 발명된 이래로, 자연어 생성 분야 뿐만 아니라 자연어 이해 분야에서도 주도적인 역할을 하고 있으며, 심지어 영상처리(Computer Vision)이나 음성인식(Automatic Speech Recognition, ASR)에서도 두각을 나타냅니다. Simple NMT에서는 Transformer를 제공함으로써 더 나은 기계번역 성능을 쉽게 얻을 수 있도록 합니다. 또한 기존의 original paper에서 제시된 vanilla Transformer 대신에, Pre-Layer-Normalized Transformer[8]를 직접 구현하여 제공합니다.
기존의 Transformer의 경우에는 비록 논문에서 제시된 성능은 매우 높았지만, learning-rate warm-up & decay 방식을 통해 학습을 진행해야 하고, 이는 Adam을 활용함에도 불구하고 또다시 learning-rate 튜닝을 진행해야 하는 어려움을 낳았습니다. 더욱이 이 learning-rate warm-up의 경우에는 hyper-paramter에 매우 취약하여, seq2seq를 이기는 것조차 어려움이 많았습니다. 이에 이러한 어려움을 타파하고자 많은 연구들[9]이 이어졌고, Pre-LN Transformer의 경우에는 learning-rate warm-up 없이 일반적인 Adam을 사용하여도 최적화가 가능하였습니다.
결과적으로 Simple NMT에서도 Transformer는 기존 Seq2seq 대비 더 빠른 학습 속도와, 훨씬 더 높은 기계번역 성능을 얻을 수 있었습니다.
Minimum Risk Training (MRT)
Simple NMT는 강화학습을 활용한 Minimum Risk Training (MRT)[4] 방식을 통해 학습하는 기능을 제공합니다.
Seq2seq와 Transformer와 같은 모델들은 기본적으로 MLE를 통해 학습하게 될 때, teacher-forcing이라는 방법을 사용합니다. Teacher-forcing은 학습할 때에 디코더의 입력에 이전 time-step의 출력 대신 정답을 넣어주어 likelihood를 구하는 것입니다. 하지만 추론의 경우에는 이전 time-step의 출력을 다음 time-step의 디코더의 입력으로 넣어주며, 샘플링 기반의 generation을 하게 됩니다. 따라서 학습과 추론이 다른 방식으로 이루어진다는 단점이 있습니다. 이러한 문제는 auto-regressive 모델 학습에서 발생하는 전형적인 문제입니다.
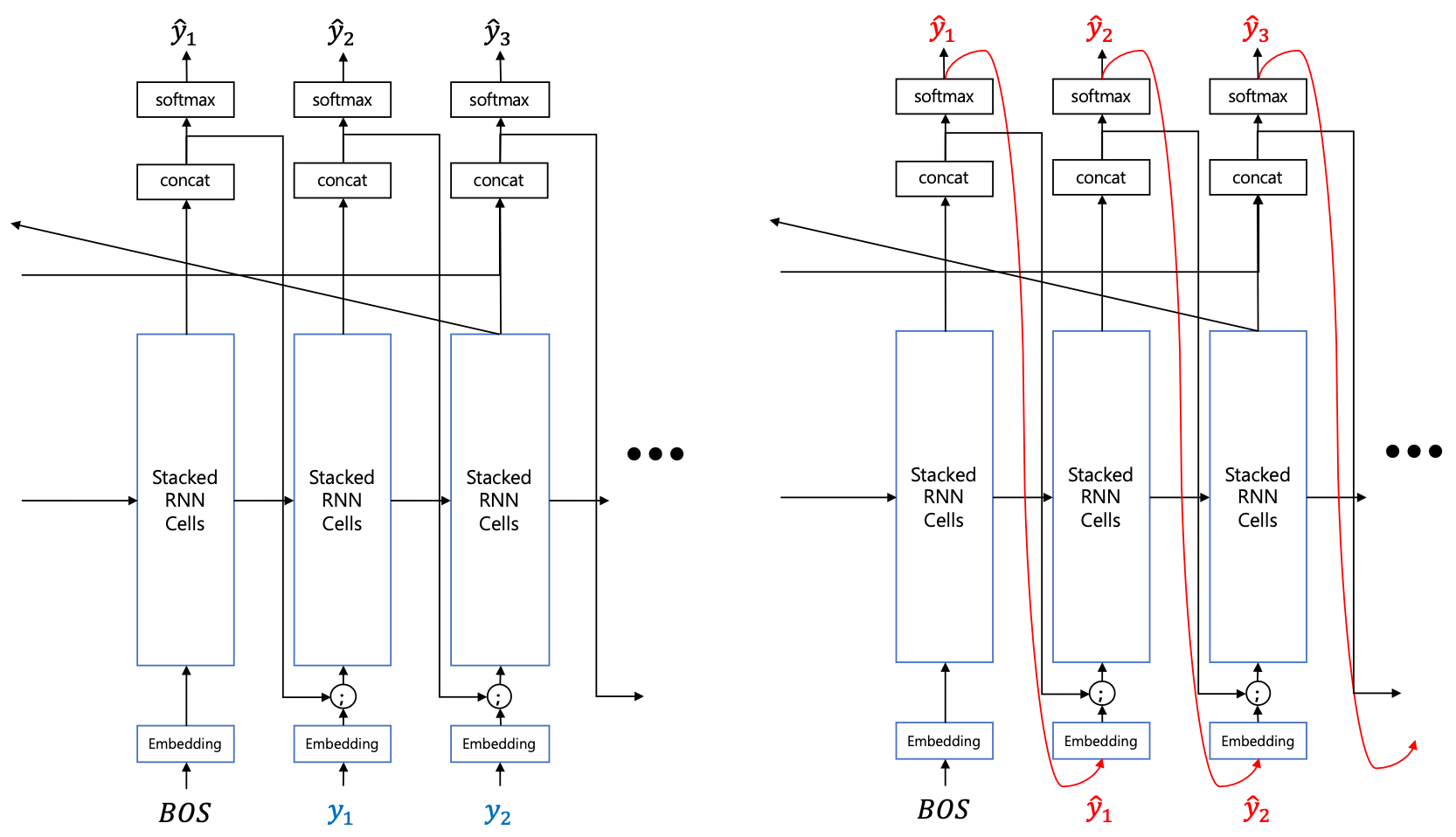
따라서 우리는 비록 teacher-forcing이 훌륭하게 동작하지만, 학습과 추론 방식의 괴리를 줄이면 더욱 잘 동작하지 않을까 기대해볼 수 있습니다. 이러한 이유에서 예전부터 MLE 기반의 teacher-forcing 대신에, 추론에서 사용하는 generation 기반의 방식을 활용하기 위한 연구가 많이 시도되었습니다.
또한 기계번역과 같은 NLG task들은 보통 BLEU나 ROUGE 등의 metric을 통해 결과를 채점하는데, PPL(Cross Entropy)을 최소화 하는 것은 BLEU나 ROUGE를 최대화 하는 것과 다른 결과를 낳을 수 있습니다. 즉, 우리의 목표는 BLEU를 최대화 하는 것이지만 PPL을 최소화 하고 있는 상황이므로, 기계번역의 성능을 극대화 하지 못하고 있을 수 있다는 것입니다. – 여기에는 BLEU가 기계번역의 품질의 꽤 정확하게 반영할 수 있다는 가정이 있습니다.
\[\begin{gathered} \mathcal{D}=\{(x_i,y_i)\}_{i=1}^N \\ \nabla_\theta\mathcal{L}(\theta)=\nabla_\theta\Big( \sum_{i=1}^N{ \log{P(\hat{y}_{i,0}|x_i)\times-\big( \text{reward}(\hat{y}_{i,0},y_i)-\frac{1}{K}\sum_{k=1}^K{ \text{reward}(\hat{y}_{i,k},y_i) } \big)} } \Big), \\ \text{where }\hat{y}_i\sim{P(\cdot|x_i;\theta)}. \\ \\ \theta\leftarrow\theta-\eta\cdot\nabla_\theta\mathcal{L}(\theta) \end{gathered}\]하지만 MRT의 경우에는 위의 수식에서 볼 수 있듯이, risk(or reward) 함수를 직접 미분할 필요가 없어, BLEU 함수를 통해 최적화를 수행할 수 있습니다. 정리해보면, MRT를 학습이 도입함으로써 우리는 아래와 같은 이점을 얻을 수 있습니다.
- 샘플링 기반 최적화를 통한 학습과 추론 방식의 괴리 최소화
- BLEU 활용을 통한 실제 번역 품질에 대한 최적화
Dual Supervised Learning (DSL)
MRT의 경우에는 뚜렷한 단점도 존재합니다. 우선 샘플링에 기반하여 학습이 진행되므로 훨씬 비효율적입니다. 샘플링에 기반한다는 것은 exploration을 많이 한다는 것이므로, 시간이 많이 소요되는 단점이 있습니다. 또한 risk 자체는 scalar 값이므로, risk를 최소화 하기 위한 정확한 방향은 알 수 없습니다. – 이에 반해 MLE의 경우에는 gradient가 나오므로 loss를 최소화 하기 위한 방향과 크기를 알 수 있습니다.
따라서 MRT와 달리, DSL[5]의 경우에는 MLE의 scheme 안에서 기존의 문제들을 해결하려 합니다. 두 문장 사이의 정보는 동일하다는 번역의 특징을 활용하여, dual learning을 통해 성능을 높이고자 합니다. 기계번역의 경우에는 DSL과 같이 이러한 특징을 활용한 연구들[10, 11]이 많이 이어져왔습니다.
\[\begin{gathered} \mathcal{L}(\theta_{x\rightarrow{y}})=\sum_{i=1}^N{ \Big( \ell\big( f(x^i;\theta_{x\rightarrow{y}}),y^i \big) +\lambda\mathcal{L}_\text{dual}(x^i,y^i;\theta_{x\rightarrow{y}},\theta_{y\rightarrow{x}}) \Big) } \\ \mathcal{L}(\theta_{y\rightarrow{x}})=\sum_{i=1}^N{ \Big( \ell\big( f(y^i;\theta_{y\rightarrow{x}}),x^i \big) +\lambda\mathcal{L}_\text{dual}(x^i,y^i;\theta_{x\rightarrow{y}},\theta_{y\rightarrow{x}}) \Big) } \\ \text{where }\mathcal{L}_\text{dual}(x^i,y^i;\theta_{x\rightarrow{y}},\theta_{y\rightarrow{x}})=\Big\| \big( \log{P(y^i|x^i;\theta_{x\rightarrow{y}})+\log{\hat{P}(x^i)}} \big)-\big( \log{P(x^i|y^i;\theta_{y\rightarrow{x}})+\log{\hat{P}(y^i)}} \big) \Big\|_2^2. \end{gathered}\] \[\nabla_{\theta_{x\rightarrow{y}}}\mathcal{L}_\text{dual}(x^i,y^i;\theta_{x\rightarrow{y}},\theta_{y\rightarrow{x}})=\nabla_{\theta_{x\rightarrow{y}}}\Big\| \big( \log{P(y^i|x^i;\theta_{x\rightarrow{y}})+\log{\hat{P}(x^i)}} \big)-\big( \log{P(x^i|y^i;\theta_{y\rightarrow{x}})+\log{\hat{P}(y^i)}} \big) \Big\|_2^2.\]위의 수식에서처럼 regularization term의 추가를 통해 auto-regressive 모델 학습에서 생길 수 있는 문제를 해결하고자 합니다.
DSL의 경우에는 MLE 위에서 동작하므로, MRT에 비해 훨씬 효율적인 최적화가 가능합니다. 다만 인코더-디코더 모델과 LM 모델을 각각 2개씩 들고 학습을 진행해야 하기 때문에, 메모리의 한계로 인해 작은 미니배치 사이즈를 사용해야 하는 한계는 존재합니다. (Transformer의 경우에는 gradient accumulation을 활용하므로 실제 파라미터 업데이트에 활용되는 샘플의 숫자는 훨씬 큽니다.)
Summary
아래의 테이블은 각 아키텍처와 알고리즘에 따른 하이퍼파라미터를 정리한 내용입니다. 아쉽게도 MRT의 경우에는 Transformer의 generation이 워낙 메모리를 많이 먹는 탓에 수행할 수 없었습니다. – 캐싱을 없애고 generation의 속도를 낮추면 가능할 수 있습니다. MRT와 DSL은 각각 MLE의 모델들을 pretrained 모델로 활용하며, 상황에 따라 다른 optimizer와 learning rate를 활용합니다.
| Hyper-param | Seq2seq (MLE) | Transformer (MLE) | Seq2seq (MRT) | Seq2seq (DSL) | Transformer (DSL) |
|---|---|---|---|---|---|
| word_vec_size | 512 | - | 512 | 512 | - |
| hidden_size | 768 | 768 | 768 | 768 | 768 |
| n_layers | 4 | 4 | 4 | 4 | 4 |
| dropout | .2 | - | .2 | .2 | - |
| batch_size | 320 | 4096 | 320 | 320 | 4096 |
| n_epochs | 30 | 30 | 30 + 40 | 30 + 10 | 30 + 10 |
| optimizer | Adam | Adam | Adam + SGD | Adam | Adam |
| learning_rate | 1e-3 | 1e-3 | 1e-3 $\rightarrow$ 1e-2 | 1e-3 $\rightarrow$ 1e-2 | 1e-3 $\rightarrow$ 1e-2 |
| max_grad_norm | 1e+8 | 1e+8 | 1e+8 $\rightarrow$ 5 | 1e+8 | 1e+8 |
또하나 눈여겨봐야 할 점은 seq2seq와의 형평성을 고려하여 Transformer의 경우에 원래 페이퍼에서 제시한 base model보다 훨씬 작은 모델이라는 것입니다. 저자는 8개의 레이어를 기본 베이스 모델로 삼았는데, 여기서는 4개의 레이어만을 가졌으며 hidden_size의 경우에도 훨씬 작습니다.
Evaluation
실험 데이터는 상기한 AI-Hub의 데이터를 활용하였습니다. 위에서 적은대로 실수로 Train/Valid/Test를 6:2:2로 나눈 바람에 train 데이터가 매우 적습니다. 이에 반해 test 데이터는 20만 문장을 전부 번역하고 BLEU를 측정하기엔 너무 힘들어서 1,000 문장만 다시 선택되었습니다. 즉, 약 19만9천 문장이 버려졌습니다.
| set | lang | #lines | #tokens | #characters |
|---|---|---|---|---|
| train | en | 1,200,000 | 43,700,390 | 367,477,362 |
| ko | 1,200,000 | 39,066,127 | 344,881,403 | |
| valid | en | 200,000 | 7,286,230 | 61,262,147 |
| ko | 200,000 | 6,516,442 | 57,518,240 | |
| valid-1000 | en | 1,000 | 36,307 | 305,369 |
| ko | 1,000 | 32,282 | 285,911 | |
| test-1000 | en | 1,000 | 35,686 | 298,993 |
| ko | 1,000 | 31,720 | 280,126 |
전처리 결과, 각 언어별 vocab 크기는 아래와 같습니다.
| en | ko |
|---|---|
| 20,525 | 29,411 |
Beam Search에 따른 성능
Simple NMT는 Beam-search 기능을 제공합니다. NLG의 경우에는 auto-regressive 속성 때문에, 단순하게 매 time-step마다 argmax를 통해 얻은 결과물은 성능이 떨어지는 경우가 많습니다. 따라서 Beam-search를 통해 우리는 NLG의 성능을 개선할 수 있습니다.
| beam_size | enko | koen |
|---|---|---|
| 1 | 31.65 | 28.93 |
| 5 | 32.53 | 29.67 |
| 10 | 32.48 | 29.37 |
위의 테이블과 같이 beam_size에 따라 BLEU 성능이 달라지는 것을 볼 수 있습니다. 기계번역 task의 경우에는 beam_size가 5에서 10 사이가 적당한 것으로 볼 수 있습니다.
아키텍처와 학습 방식에 따른 성능
Transformer의 경우에는 저자가 제안한 모델에 비해 훨씬 작은 모델임에도 불구하고, seq2seq를 압도하는 성능을 보여주고 있습니다. 심지어 Transformer의 MLE 방식은 Seq2seq의 모든 방법들보다 더 높은 성능을 보여줍니다.
MRT와 DSL의 경우에는 MLE보다 높은 성능을 보여주며, 서로간에는 비등비등한 성능을 보입니다. Transformer의 경우에도 DSL을 적용할 경우, MLE보다 더 높은 성능을 얻을 수 있는 것을 알 수 있습니다.
| enko | koen | |
|---|---|---|
| Sequence-to-Sequence (MLE) | 32.53 | 29.67 |
| Sequence-to-Sequence (MRT) | 34.04 | 31.24 |
| Sequence-to-Sequence (DSL) | 33.47 | 31.00 |
| Transformer (MLE) | 34.96 | 31.84 |
| Transformer (MRT) | - | - |
| Transformer (DSL) | 35.48 | 32.80 |
MRT: reward 함수에 따른 성능
MRT의 risk(또는 RL에서의 reward) 함수는 사용자의 필요에 따라 다르게 활용될 수 있습니다. Reward는 클수록 좋고, risk는 작을수록 좋은 값이기 때문에, 기본적으로 BLEU 함수를 활용하여 그 결과값에 -1을 곱해주면 risk로 생각할 수 있습니다. GNMT에서는 단순히 BLEU를 reward 함수로 활용할 경우 agent가 빈틈을 찾아 최적화를 시도하므로, 이를 보완한 Google BLEU (GLEU)를 제안하였습니다.
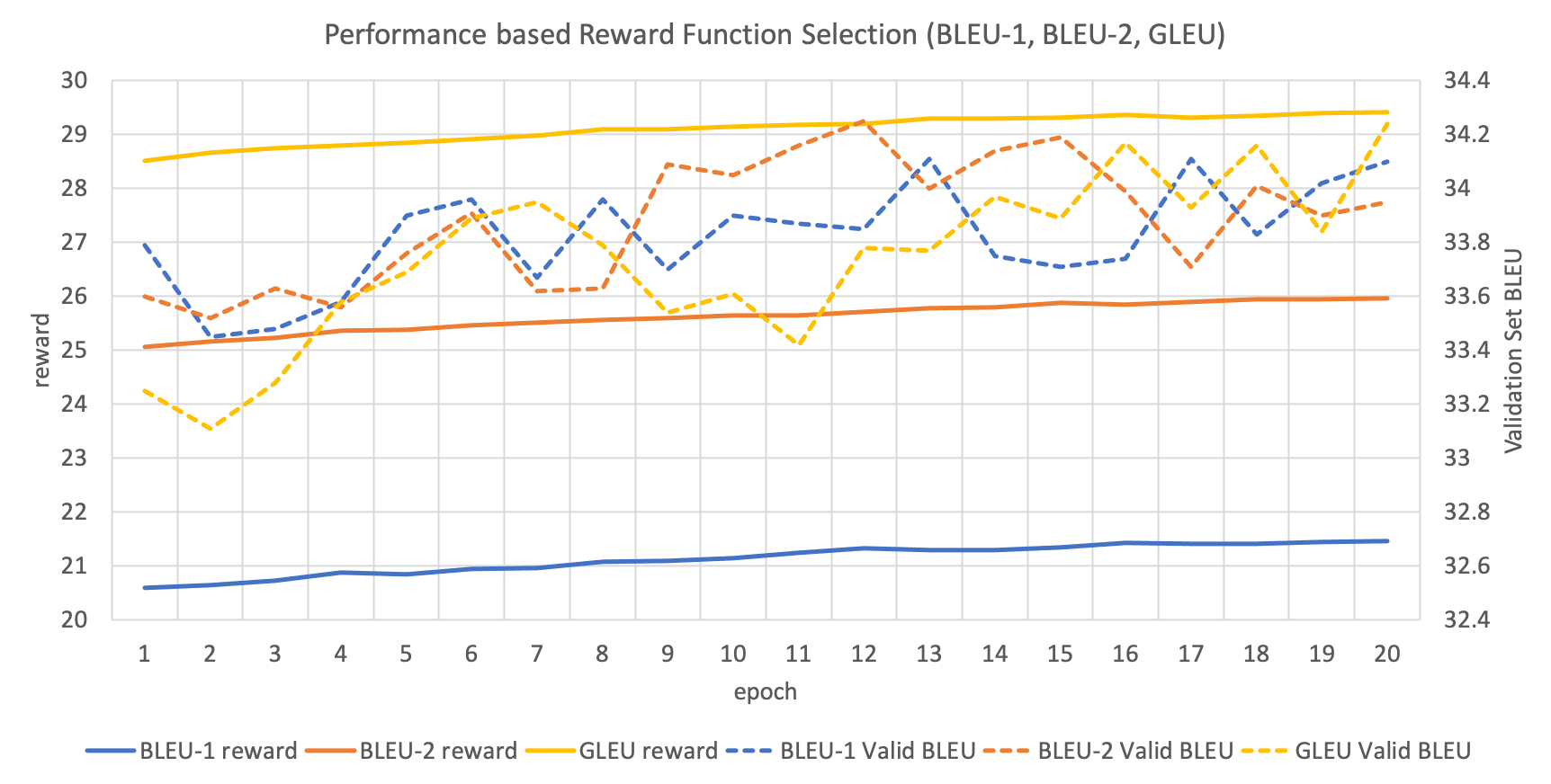
위 그래프는 각 reward 함수에 따른 train과 validation의 성능을 나타냅니다. BLEU-1과 BLUE-2는 각기 다른 smoothing 방식을 나타냅니다. 이 결과에서 주의할 점은 속도의 한계 때문에, train 할 때에는 결과 문장에 detokenization을 한 이후에 BLEU 등을 구하지 못하였고, 분절된 토큰을 그대로 둔 채로 reward 함수를 적용하였습니다. 그리고 validation set에 대해서는 detokenization까지 완료한 이후에 성능을 측정한 것입니다.
결과적으로 위 그래프를 보면 우리는 reward 함수에 대해서 성능이 크게 변하지 않음을 알 수 있습니다.
MRT: reward 함수에서 활용되는 n-gram에 따른 성능
위의 reward 함수를 적용할 때, BLEU와 GLEU 모두 얼마까지의 n-gram을 가지고 채점할지 정해줘야 합니다. 아래의 그래프는 이를 실험한 것입니다. 여기서도 위에 적은 것처럼 training 과정에서 분절되어 있는 토큰들을 기준으로 n-gram을 counting하는 것임을 주의해주세요.
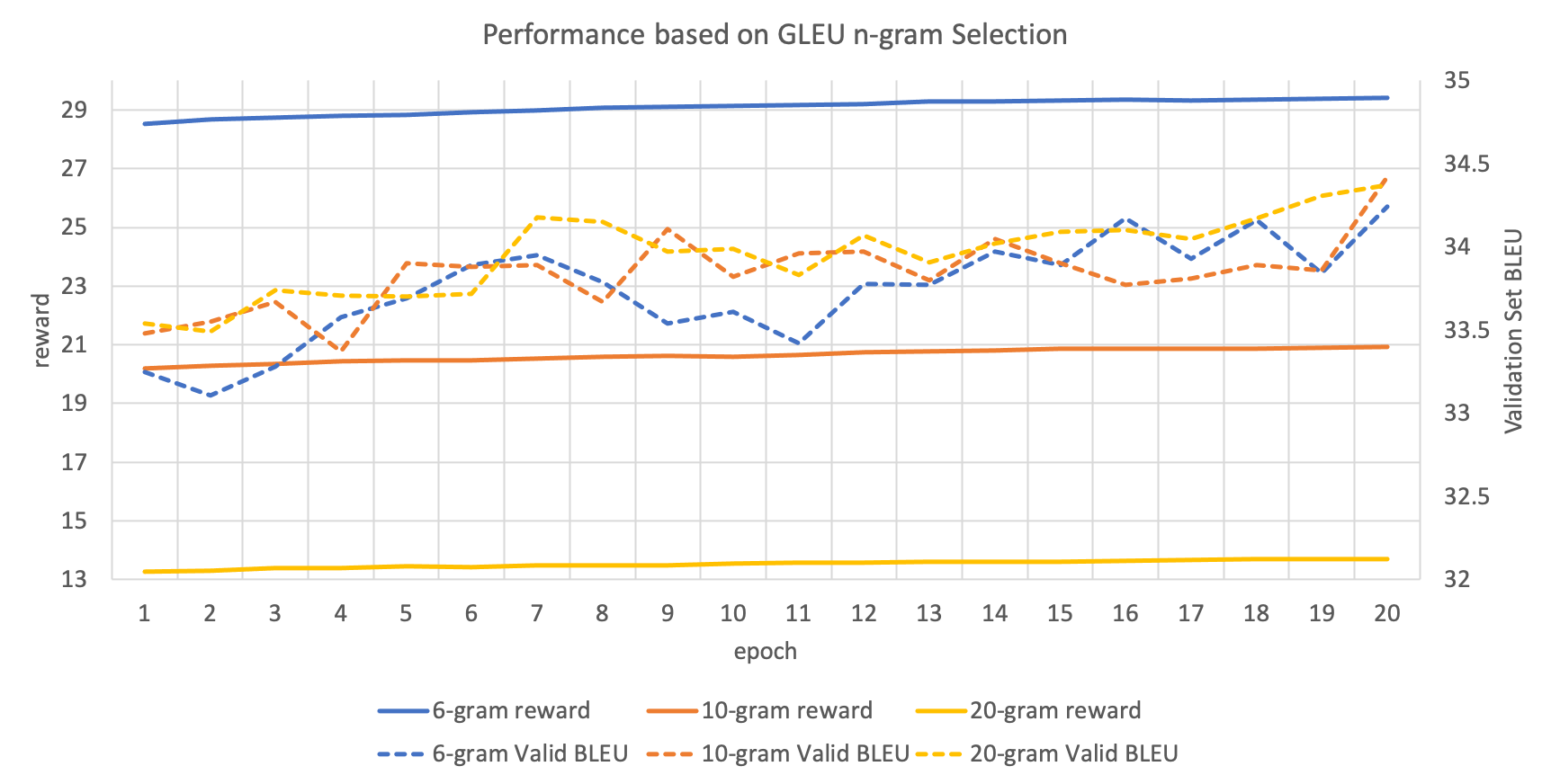
이 경우에도 딱히 어떤 n-gram을 택해야 하는지 명확한 결론을 얻을 수 없었습니다. 하지만 모든 실험 케이스에 대해서 train과 validation의 성능이 올라가는 것을 확인할 수 있습니다.
DSL: Lagrangian Multiplier( $\lambda$ )에 따른 성능
DSL은 위의 수식을 보면, regularization term이 추가된 것을 볼 수 있습니다. 이때 그래서 우리는 regularization term의 크기를 조절하여 모델의 generalization에 도움이 되도록 합니다. 그러므로 이 regularization term의 크기를 조절하는 변수(수식에서는 $\lambda$ )가 또 다른 하이퍼파라미터가 됩니다. 아래의 두 그림은 각 번역 방향 별 하이퍼파라미터에 따른 성능을 보여줍니다.
ENKO
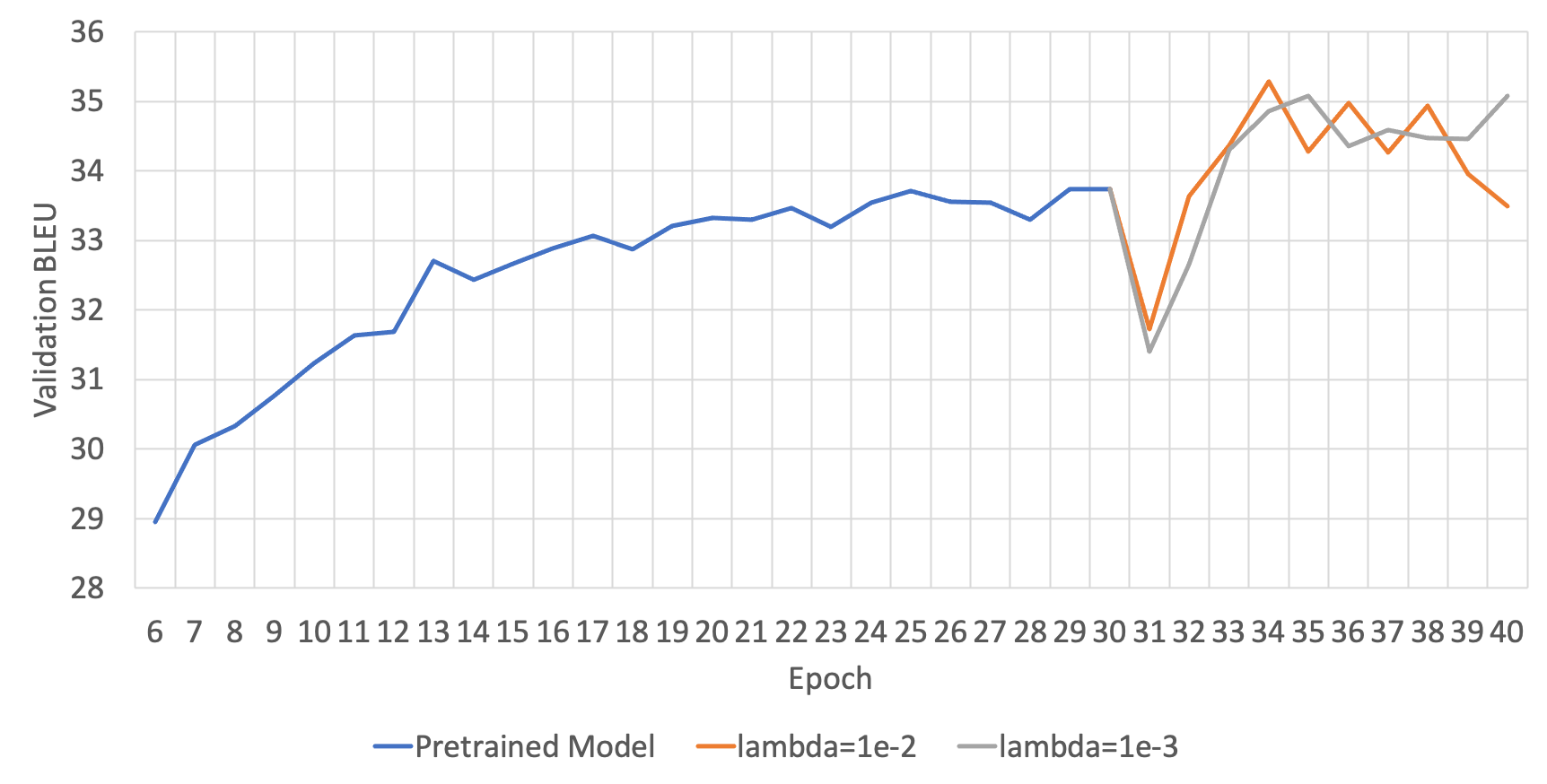
KOEN
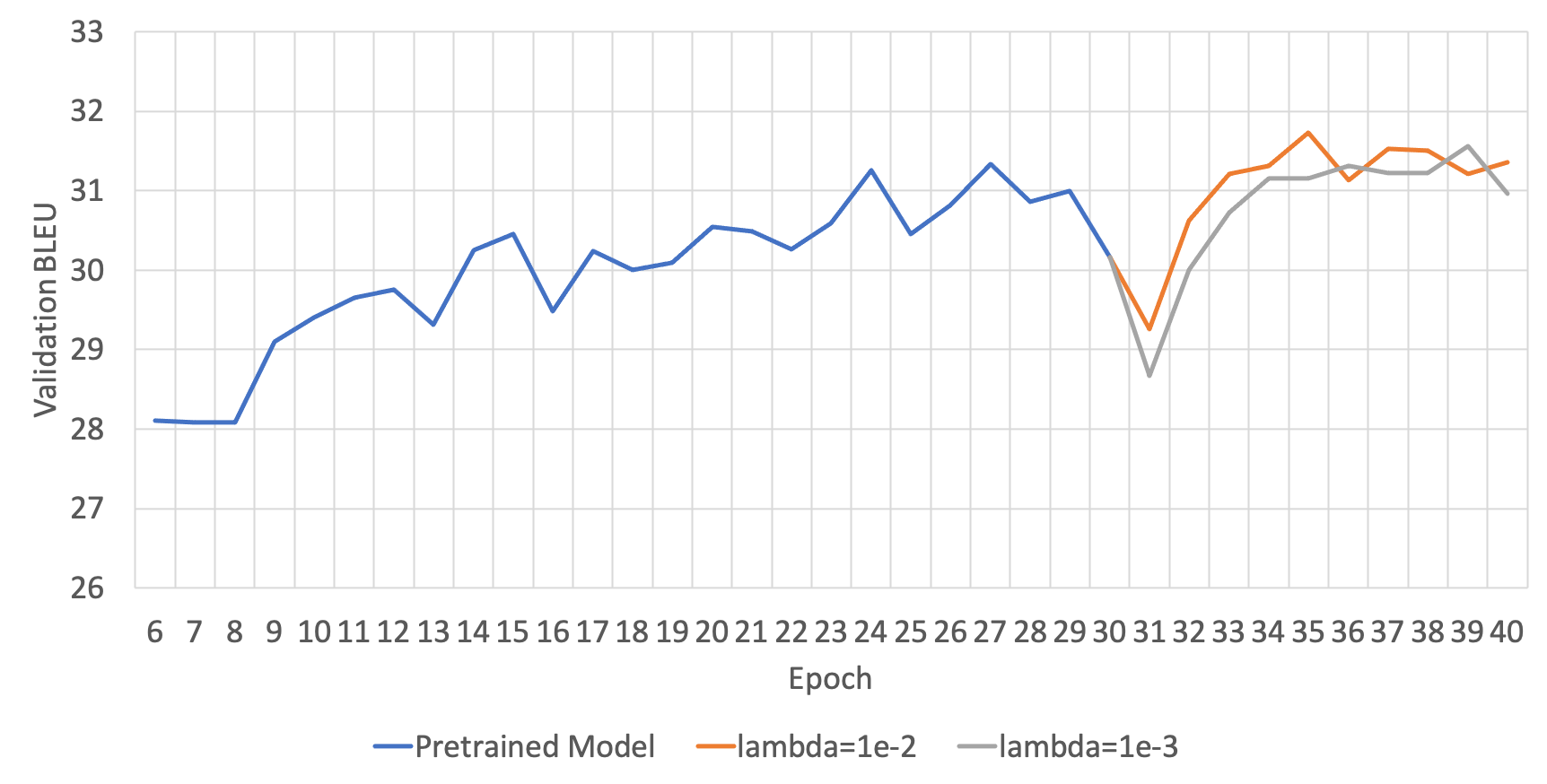
영한(ENKO)의 경우에는 딱히 lambda에 따른 성능 차의가 명확하게 드러나지 않았지만, 한영(KOEN)의 경우에는 1e-2가 더 좋은 성능을 보이는 것을 알 수 있습니다.
실제 결과 비교
일부 테스트셋의 결과를 공유합니다. Transformer가 전체 테스트셋에서는 우위를 지니지만, 일부 문장들에서는 서로 엎치락 뒷치락 하는 것을 볼 수 있습니다. 일부 문장들은 번역 결과로 미루어보건데, REF 문장도 의역이거나 완전한 번역이 아닐 것으로 추측해볼 수 있습니다.
| REF | Seq2seq (MLE) | Transformer (MLE) | Seq2seq (MRT) | Seq2seq (DSL) |
|---|---|---|---|---|
| 또한, 이건 미세 혈관을 손상해 당신이 빨간 코를 가지게 할 수 있습니다. | 또한 미세한 코를 가질 수 있는 마이너스를 손상시킬 수 있습니다. | 또한 그것은 빨간색 코를 가질 수 있는 마이크로바이옴을 손상시킬 수 있습니다. | 또한 미세혈관을 손상할 수 있어서 빨간색 코를 가지게 할 수 있습니다. | 또한, 당신을 빨간 코로 이끌 수 있는 마이크로셀들을 손상시킬 수 있습니다. |
| 예비신혼부부도 1년이내 혼인 사실이 증명 가능하면 청약할 수 있다. | 결혼을 계획하는 부부는 결혼식이 1년 이내인 경우에도 가입할 수 있다. | 결혼을 계획하고 있는 부부가 1년 이내에 결혼식이 증명될 수 있는지도 가입할 수 있다. | 결혼을 계획하는 부부도 1년 이내 결혼식이 발생할 수 있으면 가입할 수 있다. | 결혼을 계획하는 부부는 1년 이내 결혼식이 성사될 경우 가입할 수도 있다. |
| 택배 박스의 빈 곳에 한국 주소도 같이 붙여주시면 감사하겠습니다. | 택배 박스의 빈 공간에 한국 주소를 첨부하여 주시면 감사하겠습니다. | 택배 박스의 빈 공간에 대한 한국 주소를 첨부해주시면 감사하겠습니다. | 택배함의 빈 공간에 한국 주소를 첨부해주시면 감사하겠습니다. | 택배 상자의 빈 공간에 한국 주소를 첨부해 주시면 감사하겠습니다. |
| 수백만 가입자가 일상 환경에서 초고속 데이터 전송과 음성통화를 이상 없이 이용하도록 망 안정화와 업그레이드, 커버리지 확대를 지속하는 일은 최우선 과제다. | 가입자 수백만 명이 일상 환경에 문제없이 초고속 데이터 전송과 음성 호출을 이용하는 것은 네트워크 안정화, 커버리지 고도화, 커버리지 확대 등이 최우선 과제다. | 네트워크 안정화, 업그레이드, 커버리지 확대 등은 수백만 명의 가입자가 고속 데이터 전송과 음성통화를 일상 환경에서 별다른 문제 없이 이용할 수 있는 최우선 순위다. | 수백만 명의 가입자가 일상 환경에 문제 없이 초고속 데이터 전송과 음성통화를 이용하는 것이 네트워크 안정화, 업그레이드, 확대 안정성이 최우선이다. | 가입자 수백만명이 일상 환경에서 문제없이 고속 데이터 전송과 음성통화를 이용할 수 있도록 네트워크를 안정화하고, 커버리지를 확대·확대하는 것이 최우선 과제다. |
| 단기적으로 시장의 변동성은 지속될 것으로 전망되지만 역사적 관점에서 볼 때 최근 시장의 변동성이 특별히 극심한 것은 아니며 장기적인 시장 펀더멘털 역시 여전히 견고해 보인다. | 단기적으로 시장 변동성은 지속될 것으로 전망되지만 역사적 관점에서 보면 최근 시장의 변동성이 특별히 극단적이지 않고 장기간 시장 펀더멘털도 남아 있는 것으로 보인다. | 단기적으로는 시장 변동성이 지속될 것으로 전망되지만, 역사적 관점에서 보면 최근 시장 변동성은 특별히 극단적이지 않고 장기적 시장 펀더멘탈도 여전한 것으로 보인다. | 단기적으로 시장 변동성이 이어질 것으로 전망되지만 역사적 관점에서 최근 시장의 변동성은 특별히 극적으로 극단적이지 않고 장기적인 시장 펀더멘털도 남아 있는 것으로 보인다. | 단기적으로 시장 변동성이 지속될 것으로 전망되지만 역사적 측면에서 보면 최근 시장의 변동성은 특별히 극단적이지 않고 장기적인 시장 근본성도 남아 있는 것으로 보인다. |
| 기존 플라잉 프로브는 제품의 가격이 너무 고가인 데다 ICT와 같은 기존 시험 장비에 비해 시험 시간이 길어서 양산라인에 적용하기 어렵다는 단점이 있다. | 기존 비행조사는 제품 가격이 너무 높고 시험시간도 ICT 등 기존 테스트 장비보다 길기 때문에 양산 라인을 적용하기가 어렵다. | 기존의 비행용 탐사선은 제품 가격이 너무 비싸고 시험시간이 ICT 등 기존 시험 장비에 비해 길기 때문에 양산선에 적용하기 어렵다. | 기존의 비행 탐사선은 제품 가격이 너무 높고, 시험시간이 ICT 등 기존 테스트 장비보다 길기 때문에 양산 라인에 적용하기 어렵다. | 기존 플라잉 프로브는 제품 가격이 너무 높고, 시험시간이 ICT 등 기존 시험 장비보다 길어 양산 라인에 적용하기 어렵다. |
| 장우혁의 이번 공연이 성황리에 마무리된 것은 놀랄 만한 일이다. | 장우혁의 활약이 성황리에 마무리되었다는 점은 놀라운 일이다. | 장우혁의 활약이 성공적으로 마무리 된 것은 놀라운 일이다. | 장우혁의 공연이 성공적으로 마무리되었다는 점은 놀라운 일이다. | 장우혁의 활약이 성공적으로 마무리되어 놀라움을 금할 수 없다. |
| 문희상 의원은 조문 후 기자들과 만나 “나라가 소용돌이 한복판에 놓였을 때 국가의 큰 어르신 가르침이 그 어느 때보다 아쉬운데 돌아가시게 돼 진심으로 애도를 표한다”고 말했다. | 문재인 의원은 조의 끝에 기자들과 만나 “국가가 소용돌이에 빠져 있을 때 큰 고령화를 줄 수 있는 사람이 분실이라는 점에 진심으로 애도를 표한다”고 말했다. | 문희상 의원은 조문이 끝난 뒤 기자들과 만나 “국가가 소용돌이 속에 있을 때 위대한 옛 가르침을 줄 수 있는 사람을 잃었다는 것에 대해 진심으로 애도의 뜻을 표한다”고 말했다. | 문재혁 의원은 애도한 뒤 기자들과 만나 “소용돌이 한복판이 있을 때 큰 가르침을 줄 수 있는 사람의 손실이라는 것에 진심으로 애도를 표한다”고 말했다. | 문희상 의원은 조문 끝에 기자들과 만나 “국가가 소용돌이에 한창일 때 훌륭한 가르침을 줄 수 있는 사람의 상실이라는 애도를 표한다”고 말했다. |
| 한 은행권 관계자는 “기존에는 자체 DSR 기준에 걸려도 심사역이 승인하면 대출이 가능했는데, 관리지표로 본격 도입되면 사실상 대출이 어려워질 것”이라고 전했다. | 은행권 관계자는 “예전에는 자체 DSR 기준에 해당돼도 심사팀이 대출을 승인하면 대출을 할 수 있었는데, 경영지표로 도입되면 실질적으로 대출을 받기 어려울 것”이라고 말했다. | 은행권 관계자는 “과거 심사팀이 자체 DSR 기준에 해당하더라도 대출을 승인하면 대출을 받을 수 있는데 관리지표로 도입되면 사실상 대출을 받기 어려울 것”이라고 말했다. | 은행권 관계자는 “기존에는 자체 DSR 기준에 해당하더라도 심사단이 대출을 승인하면 대출할 수 있었지만 관리지표로 도입하면 사실상 대출을 받기 어려울 것”이라고 말했다. | 한 은행 관계자는 “과거에는 자체 DSR 기준에 해당하더라도 심사팀이 대출을 승인하면 대출을 할 수 있었지만 경영지표로 도입되면 실제로는 대출을 받기 어려워진다”고 말했다. |
| 사회적 감사는 업무가 법규나 규정에는 부합하더라도 공평성이나 형평 등 사회적 규범에 맞지 않는다면 이를 개선하도록 권고해 조직에 변화를 유도하는 것이다. | 사회적 감사는 법이나 규정을 준수하더라도 정의나 형평성 등 사회적 규범에 부합하지 않으면 업무 윤리 개선을 시키도록 유도하는 등 조직의 변화를 유도하는 것이다. | 사회감사에서는 법이나 규정을 준수하더라도 정당이나 형평 등 사회규범에 맞지 않으면 업무 윤리가 향상될 수 있도록 독려해 조직의 변화를 유도한다. | 사회적 감사는 법이나 규정을 준수하더라도 정의나 형평성 등 사회적 규범을 충족하지 않으면 업무 윤리 개선을 유도해 조직의 변화를 격려하고 있다. | 사회적 감사는 법이나 규정을 준수하더라도 정의나 형평 등 사회적 규범에 부합하지 않을 경우 업무 윤리 개선을 유도해 조직의 변화를 유도하도록 유도한다. |
| 마찰이 있더라도 국익 차원에서 인터넷 역차별 해소 정책을 강력하게 추진해야 한다는 목소리가 힘을 얻기 시작했다. | 마찰이 일어나더라도 인터넷 역차별 정책의 해법을 구현하는 목소리가 국익을 향한 힘을 얻기 시작했다. | 마찰이 발생해도 인터넷 역차별 정책의 해법을 시행하자는 목소리가 국익을 위해 힘을 얻기 시작한 것이다. | 마찰이 발생하더라도 인터넷 역차별 정책의 해법을 구현하는 목소리가 국익을 위해 힘을 얻기 시작했다. | 마찰이 발생하더라도 인터넷 역차별 정책의 해법을 구현해야 한다는 목소리가 국민적 관심에 힘을 받기 시작했다. |
| 오비맥주가 주요 맥주 제품의 가격을 인상키로 하면서 하이트진로와 롯데주류 등도 조만간 맥주 가격을 올릴 가능성이 높아졌다. | 오비맥주가 각종 맥주 상품 가격을 올리기로 결정한 만큼 하이트진로와 롯데주류도 가까운 시일 내에 맥주 가격을 인상할 가능성이 높다. | 오비맥주가 다양한 맥주 제품 가격 인상 결정을 내린 만큼 하이트진로와 롯데주류도 가까운 장래에 맥주 가격을 인상할 가능성이 높다. | 오비맥주가 다양한 맥주 상품의 가격을 올리기로 결정하면서 하이트진로와 롯데주류도 가까운 미래에 맥주 가격을 인상할 가능성이 높다. | 오비맥주가 다양한 맥주 상품의 가격 인상을 결정한 만큼 하이트진로와 롯데주류도 가까운 시일 내에 맥주 가격을 인상할 가능성이 높다. |
| 이 사고로 통학차량에 타고 있던 학생 7명(남3, 여4) 중 고교생 3명과 여중생 1명이 다쳐 인근 병원으로 옮겨쳐 치료를 받고 있다. | 이 사고로 통근차량에 타고 있던 학생 7명 가운데 고등학생 3명과 여중생 1명이 부상을 입고 인근 병원으로 옮겨져 치료를 받고 있다. | 통학 차량에 타고 있던 학생 7명 중 고등학생 3명과 여중생 1명이 부상을 입고 인근 병원으로 옮겨져 치료를 받고 있다. | 이 사고로 통학차량에 타고 있던 학생 7명 중고생 3명과 여중생 1명이 다쳐 인근 병원으로 옮겨져 치료를 받고 있다. | 통학차량에 타고 있던 학생 7명 가운데 고등학생 3명과 여중생 1명이 다쳐 인근 병원으로 옮겨져 치료를 받고 있다. |
| 반경 1km 내에 용현초, 신광초, 신흥여중 등 다수의 교육시설이 위치해 있고 홈플러스와 현대 유비스 병원 등이 도보 5분 거리 내에 위치해있다. | 1㎞ 이내에는 용인초등학교, 신광초등학교, 신흥여중 등 수많은 교육시설이 있으며, 걸어서 5분 거리에 홈플러스, 현대위비병원 등이 있다. | 1km 이내에는 용현초등학교, 신왕초, 신흥여자중학교 등 수많은 교육시설이 있으며 도보 5분 거리에 홈플러스와 현대 유비에스 병원이 있다. | 1㎞ 안에는 용현초등학교, 신광초등학교, 신흥여학교 등 수많은 교육시설이 있으며, 5분 도보 거리에는 홈플러스와 현대유비병원이 있다. | 1km 이내에는 용현초등학교, 신왕초, 신흥여중 등 수많은 교육시설이 있으며 도보 5분 거리에 홈플러스와 현대유비병원이 있다. |
Conclusion
이번 포스팅에서는 패스트캠퍼스의 자연어 생성 클래스의 기계번역 실습을 자세히 다뤄 보았습니다. 실제로 MRT와 DSL의 경우에는 MLE 방식보다 더 좋은 성능을 이끌어 낼 수 있음을 확인할 수 있었습니다. 또한 지금의 자연어처리 학계를 지배하고 있는 Transformer의 경우에는, Seq2seq의 어떠한 최적화 방식보다도 더 좋은 성능을 거둘 수 있었습니다. 이를 통해 우리는 Transformer의 대단함을 다시한번 느낄 수 있습니다.
사실 자연어 생성 클래스는 기존의 다른 강의들에 비해서 훨씬 난이도가 높은 것이 사실입니다. 특히, MRT를 다루기 시작하면서부터 수식의 빈도가 급격하게 증가하는데요. 예전 오프라인 강의를 진행 할때도 이 부분부터 수강생 분들도 힘들어하는 것을 느낄 수 있었습니다. 제 개인적인 경험에 비춰 보면 MRT나 DSL을 제대로 구현하기 위해서는 수식을 정확하게 이해하는 것이 중요했는데요. 수식을 정확하게 이해하고 이를 코드로 옮기는 과정에서 한단계 더 성장할 수 있었습니다. 그래서 저는 수강생 분들이 MRT나 DSL을 배우셨으면 하는 마음에서도 이 내용을 강의에 넣었지만, 수식을 이해하고 이를 코드로 옮기는 과정을 체득하셨으면 하는 바램이 더 큽니다. 꼭 제 강의를 수강하시는 분들이 아니더라도, 이 포스팅과 Simple NMT를 참고하여 수식을 코드로 옮기는 과정을 체득할 수 있으면 좋겠습니다.
References
- [1] Sutskever et al., Sequence to Sequence Learning with Neural Networks, NIPS, 2014
- [2] Bahdanau et al., Neural Machine Translation by Jointly Learning to Align and Translate, ICLR, 2015
- [3] Vaswani et al., Attention is All You Need, NIPS, 2017
- [4] Shen et al., Minimum Risk Training for Neural Machine Translation, ACL, 2016
- [5] Xia et al., Dual Supervised Learning, PMLR, 2017
- [6] Sennrich et al., Neural Machine Translation of Rare Words with Subword Units, ACL, 2016
- [7] Micikevicius et al., Mixed Precision Training, ICLR, 2018
- [8] Xiong et al., On Layer Normalization in the Transformer Architecture, OpenReview, 2019
- [9] Liu et al., On the Variance of the Adaptive Learning Rate and Beyond, ICLR, 2020
- [10] Xia and He et al., Dual Learning for Machine Translation, NIPS, 2016
- [11] Wang et al., Dual Transfer Learning for Neural Machine Translation with Marginal Distribution Regularization, AAAI, 2018
- [12] Luong et al., Effective Approaches to Attention-based Neural Machine Translation, ACL, 2015