Autoencoder based Anomaly Detection
이번 포스팅에서는 오토인코더 기반의 이상탐지(anomaly detection)에 대해서 살펴보도록 하겠습니다. 오토인코더는 입력을 그대로 출력(복원)해내도록 하는 목적 함수를 갖습니다. 따라서 보통 MSE 손실 함수를 사용하며, 중간에 bottle-neck(병목)이 있어 고차원 공간 상의 입력 데이터를 저차원의 공간으로 맵핑(mapping)하여 잠재적인 변수로 표현(latent representation)하였다가, 다시 입력과 같은 고차원의 공간으로 복원해내야 합니다.
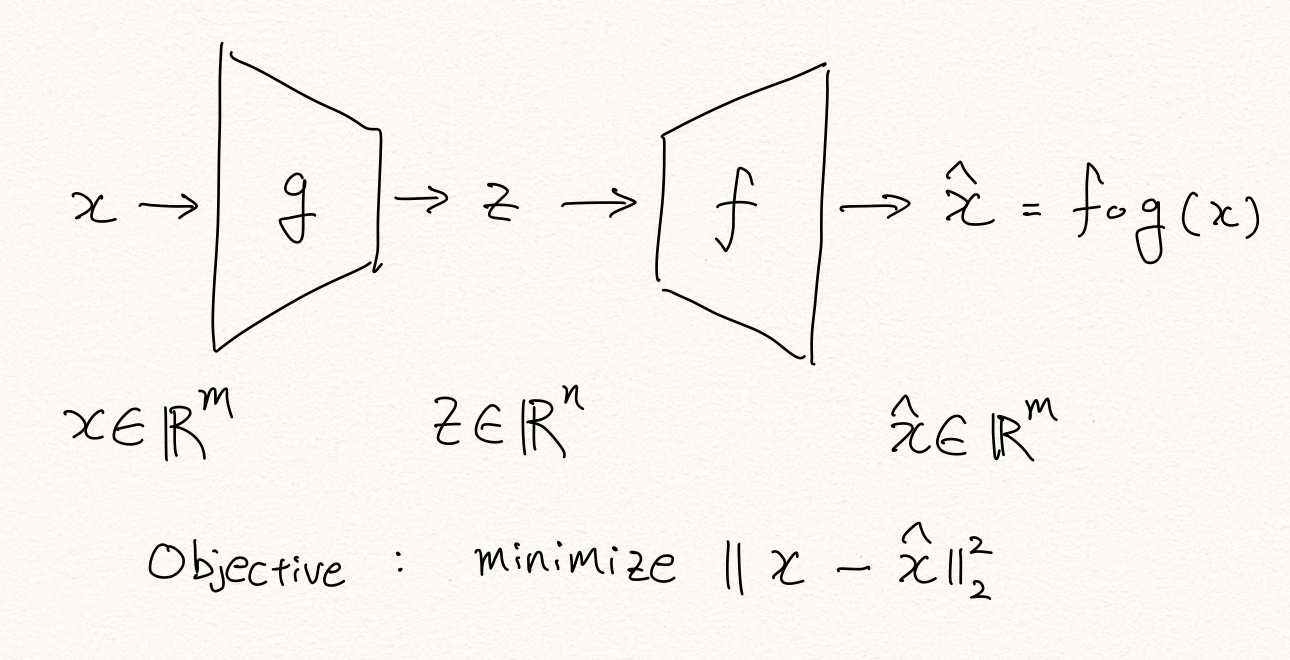
여기서 인코더와 디코더는 여러개의 non-linear 계층을 가질 수 있으며, non-linear activation function을 없애서 linear한 형태로 오토인코더를 구성할 경우 PCA 처럼 동작하게 됩니다.
Anomaly Detection with AE
오토인코더를 활용하여 이상탐지를 수행하는 과정은 다음과 같습니다.
- 입력 샘플을 인코더를 통해 저차원으로 압축합니다.
- 압축된 샘플을 디코더를 통과시켜 다시 원래의 차원으로 복원합니다.
- 입력 샘플과 복원 샘플의 복원 오차(reconstruction error)를 구합니다.
- 복원 오차는 이상 점수(anomaly score)가 되어 threshold와 비교를 통해 이상 여부를 결정합니다.
- threshold 보다 클 경우 이상으로 간주
- threshold 보다 작을 경우 정상으로 간주
위의 과정에서 오토인코더는 복원 오차를 최소화하기 위해서 병목 구간을 지날 때, 최소한의 정보량을 잃기 위해 자동으로 학습될 것입니다. 즉, MNIST의 예로 들면, 주변부의 항상 숫자가 존재하지 않는 뻔한 pixel들은 굳이 기억하지 않아도 될 것이고, 중간 pixel들을 좀 더 효율적으로 기억하도록 할 것입니다.
그럼 비정상 샘플이 테스트 과정에서 주어질 경우, 오토인코더는 주어진 샘플에 대해서 효과적으로 압축과 복원을 수행하지 못할 것입니다. 결국 주어진 샘플들의 특징을 잘 추출해내지 못할 것이므로, 복원 오차(reconstruction error)는 커질것이므로 비정상 샘플로 판별할 수 있습니다.
하지만 때때로 표현에 필요한 최적의 병목 구간 크기에 비해서 실제 병목 구간의 크기가 너무 클 경우(극단적인 경우에는 입력 샘플과 크기가 같을수도), 오토인코더는 identity function이 되어 입력을 그대로 복사해내는 능력을 갖게 될 것입니다. 즉, 학습 과정에서 보지 못했던 비정상 샘플이 주어져도 그냥 그대로 복사해버리는 능력을 가질 수 있습니다. 따라서 우리는 병목 구간의 크기를 하이퍼 파라미터(hyper-parameter)로써 적절하게 잘 조절할 필요성이 있습니다.
Nonlinear Dimension Reduction (AE)
오토인코더도 차원 축소를 통해 특징(feature)을 추출 하는 방법을 학습합니다. 다만 비선형적인 차원 축소를 다룬다는 점에서 PCA와 큰 차이점을 지닙니다. 하지만 차원 축소를 다룬다는 점에서 여러가지 생각할 점들이 많습니다.
Manifold Hypothesis
먼저 우리는 매니폴드(Manifold) 가설 관점에서 생각해 볼 수 있습니다. 아래의 수식 및 설명은 NIPS 2018에서 발표된 GPND(Generative Probabilistic Novelty Detection with Adversarial Autoencoders) [1] 에서 제시한 방법으로 매니폴드와 오토인코더의 관계를 잘 설명해 줍니다.

위의 설명에 따르면 우리에게 주어진 데이터 샘플 $x$ 는 매니폴드 $f(z)$ 에 노이즈 $\xi$ 가 더해진 형태가 됩니다.
\[x=f(z)+\xi\]이때 저차원 공간에서 고차원 공간으로의 맵핑 함수 $f$ 에 의해서 정의된 매니폴드 $\mathcal{M}$ 에 $f(z)$ 가 속하는 것을 알 수 있습니다. 그리고 저차원의 $z$ 가 속하는 공간 $\Omega$ 가 정상 데이터들의 집합임을 알 수 있습니다. 즉, 인코더를 통과시키는 과정은 고차원에서 저차원으로의 맵핑 과정일 뿐만 아니라 노이즈 $\xi$ 를 제거하는 작업(denoising)임을 알 수 있고, 이 노이즈의 크기에 따라서 정상이냐 비정상이냐를 결정하는 것이라고 생각해 볼 수 있을 것입니다.
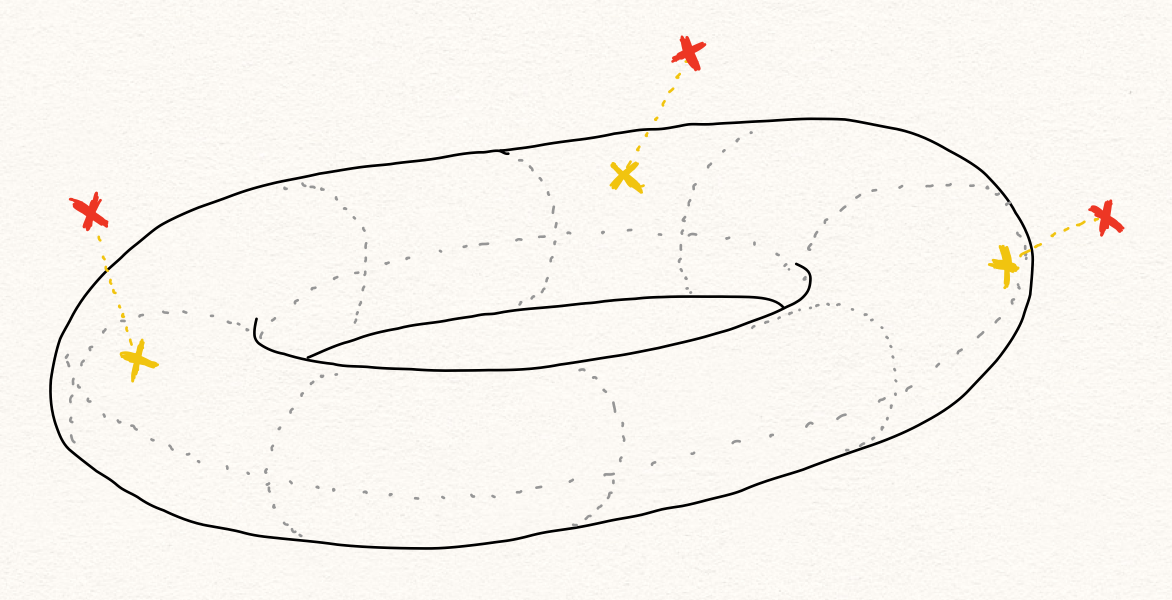
다르게 표현하면, 오토인코더에 샘플을 통과시키는 것은 매니폴드 표면 $\mathcal{M}$ 에 투사(projection)하는 과정[2]이라고 볼 수 있고, 이는 디노이징이라고 볼 수 있으며, 그 결과 복원 오차(reconstruction error)가 발생하는 것이라고 볼 수 있습니다.
Latent space
오토인코더는 학습 데이터 내에서 샘플을 잘 설명할 수 있는 특징(feature)을 추출해냅니다. 이것은 PCA에서 분산(variance)을 최대화 하는 방향으로 PC를 찾는 것과 비슷하다고 볼 수 있을 것입니다. 좁은 bottle-neck을 통과해야 하기 때문에, 정보량이 높은 특징들을 우선적으로 추출해 낼것 입니다. [3, 5, 6] 결과적으로 인코더의 레이어를 통과하면서 복원에 덜 필요한 특징들은 버려지게 됩니다. 즉, 각 레이어의 결과물들은 복원에 필요한 정보들이 남아있게 됩니다.
이러한 의미에서 이상적인 상황에서 잠재 공간(latent space)에 표현된 latent(or hidden) representation은 비정상 데이터에 대한 정보는 남아있지 않습니다. 즉, 비정상 데이터를 통과시키더라도, 정상 데이터와 다름을 알려줄 수 있는 (비정상 데이터에 대한) 정보는 남아있으리라는 보장이 없습니다.
Relationship between $P(x)$ and $P(z)$
해당 관점에서 $P(x)$ 가 낮은 샘플 $x$ 를 찾고자 하는 이상 탐지 문제에서 잠재 공간에서의 확률 분포 $P(z)$ 를 살펴보는 것은 큰 도움이 되지 않을 가능성이 높습니다. 흔히 비정상 샘플 $\tilde{x}$ 가 있을 때, 비정상 샘플은 정상 샘플 $x$ 와 비슷하지 않으므로 고차원의 공간 상에서 $P(x)$ 분포의 밀도가 낮은 곳에 위치할 가능성이 높다고 생각할 것입니다. 따라서 $\tilde{x}$ 의 인코딩 결과값 $\tilde{z}$ 의 확률값 $P(\tilde{z})$ , 또한 낮지 않을까 생각 할 수 있습니다.
하지만 앞서 서술한대로, latent space에는 학습 데이터를 잘 설명하기 위한 특징들만 정의되어 있기 때문에, 비정상 샘플 또한 정상 특징들로만 표현될 것입니다. 따라서 정상 특징들의 조합으로 이루어진 비정상 샘플의 hidden representation은 정상 샘플의 그것과 크게 다르다는 보장이 없습니다. 따라서 $P(z)$ 를 활용하여 $P(x)$ 가 낮은 것을 판별하는 것은 쉽지 않은 일이 될 것 입니다.
$P(z)$ 를 보는 것은 unimodal normality case를 가정한 문제 정의 아래에서는 괜찮은 접근 방법일 수 있습니다. 정상 데이터의 패턴이 크게는 하나라고 볼 수 있기 때문에, $P(x)$ 를 gaussian distribution 형태의 $P(z)$ 로 mapping 할 수 있고, 이때에는 $P(x)\varpropto{P(z)}$ 라고 가정하는 것은 가능합니다. 따라서 위의 unimodal normality case 가정을 따른 논문들은 $P(z)$ 를 anomaly score를 구하는데 사용합니다. [1] 하지만 아래의 그림과 같이 이런 가정은 multimodal normality case에서는 동작하지 않을 수 있습니다.
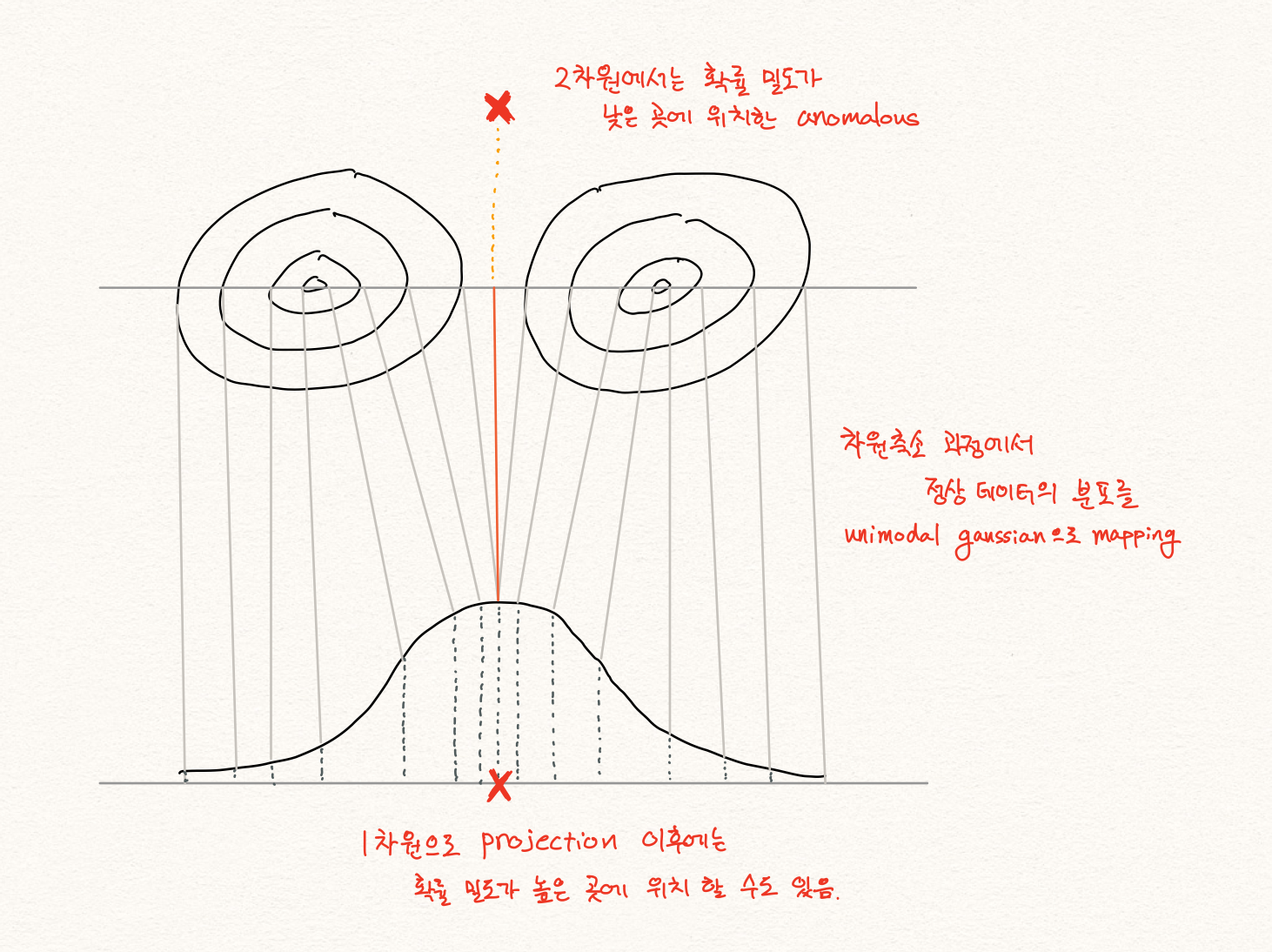
다른 관점에서 $P(x)\varpropto{P(z)}$ 에 대한 간단한 반례에 대해 생각해 볼 수 있습니다. 우리는 기본적으로 복원 오차(reconstruction error)를 활용하여 anomaly score를 구합니다.
만약 우리에게 정상 샘플 $x$ 가 있고, 이를 복원한 샘플 $\hat{x}$ 이 있다고 해보겠습니다. 이때 비정상 샘플 $\tilde{x}$ 가 주어졌고, 우연히 복원한 결과 똑같은 아까와 똑같은 복원 샘플 $\hat{x}$ 을 얻었다고 해보겠습니다. 여기서 우리의 오토인코더는 매우 뛰어나게 잘 동작했기 때문에 $||x-\hat{x}||=0$ 이라는 결과를 얻었다고 합시다. 그럼 $||x-\hat{x}||\ll||\tilde{x}-\hat{x}||$ 이 성립할 것입니다.
결과적으로 디코더가 저차원에서 고차원으로 가는 1:1 함수라고 가정한다면(현실은 ReLU를 사용한다면 다대일 함수일 가능성이 높습니다.), 인코더 함수 $f$ 에 대해서 $f(x)=f(\tilde{x})$ 라고 볼 수 있고, 이는 latent space에서 $P(z)$ 가 낮은지 확인하는 것은 $P(x)$ 가 낮은것을 확인하는 것을 보장하지 않는 것임을 알 수 있습니다.
Variational Autoencoders
2014년 Kingma는 Auto-Encoding Variational Bayes [4]라는 논문을 통해 VAE(Variational Autoencoders)를 발표합니다. 이 논문에서 VAE는 reparameterization trick을 활용하여 인코더가 뱉어낸 분포의 파라미터( $\mu,\sigma$ )로부터 latent variable $z$ 를 샘플링하고, 이로부터 posterior distribution $p(x|z)$ 를 근사(approximate)합니다.
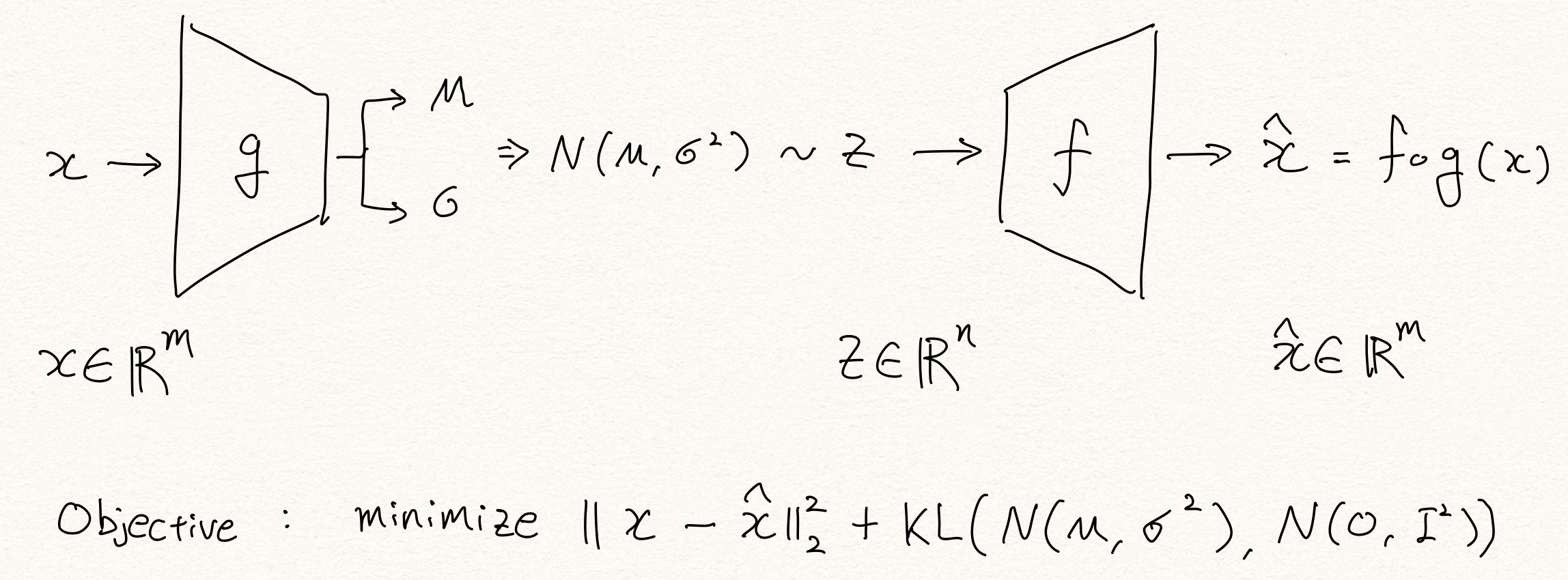
이 과정에서 유도된 수식에 의해 KL-divergence 항이 추가 되어 regularization 역할을 수행합니다.
\[\log{p(x)}\ge\mathbb{E}_{\text{z}\sim{p(z|x;\theta)}}\big[\log{p(x|\text{z};\phi)}\big]-\text{KL}\big(p(\text{z}|x;\theta)||p(\text{z})\big)\]Variational Information Bottleneck
이때 VAE의 KLD term은 이상 탐지에서 매우 훌륭한 역할을 수행합니다. Information bottleneck theory [3, 5, 6]는 심층신경망이 학습되는 원리에 대해서 설명하고자 하는 이론입니다. 오토인코더의 병목 구간과 같이 차원 축소의 과정에서 중요한 특징(feature)을 추출하는 방법이 자동으로 학습될 수 있다는 내용입니다. (사실 우리는 오토인코더가 아니더라도 보통 차원 축소가 되도록 신경망을 구성합니다.) 이 정보의 병목(information bottleneck)은 자연스럽게 각 레이어별로 mutual information이 최대화 되도록 하며, 이 과정에서 mutual information을 최대화 하는 것과 상관 없는 특징들은 자연스럽게 떨어져 나갑니다.
VAE의 흥미로운 점은 Variational Information Bottleneck (VIB) [7]을 제공한다는 점 입니다. 오토인코더(AE)는 물리적으로 레이어의 출력 유닛 갯수를 점차 줄여나가며 병목 구간에서 최종적인 information bottleneck을 걸게 되지만, VIB는 수식에 의해서 자연스럽게 가상의 information bottleneck을 갖게 됩니다.
VAE의 수식에는 KLD 항 $\text{KL}\big(p(\text{z}|x)||p(\text{z})\big)$ 이 있는데요, $\log{p(x)}$ 을 최대화 하기 위해서는 자연스럽게 KLD 항을 최소화 해야 합니다. 이 관점에서 KLD 항을 풀어보면 아래와 같습니다.
\[\begin{aligned} \text{KL}\big(p(\text{z}|x)||p(\text{z})\big)&=-\mathbb{E}_{\text{z}\sim{p(\text{z}|x)}}\bigg[\log{\frac{p(\text{z})}{p(\text{z}|x)}}\bigg] \\ &=\mathbb{E}_{\text{z}\sim{p(\text{z}|x)}}\bigg[\log{\frac{p(\text{z}|x)}{p(\text{z})}}\bigg] \\ &=\mathbb{E}_{\text{z}\sim{p(\text{z}|x)}}\bigg[\log{\frac{p(x,\text{z})}{p(x)\cdot{p(\text{z})}}}\bigg] \\ \end{aligned}\]이때, 아래와 같이 mutual information (MI) 수식과 비교해볼 수 있습니다.
\[\begin{aligned} \text{I}(Z;X)&=\sum_{X\in\mathcal{X}}P(X)\sum_{Z\in\mathcal{Z}}P(Z|X)\log{\frac{P(X,Z)}{P(X)\cdot{P(Z)}}} \\ &=\mathbb{E}_{Z\sim{P(Z|X),X\sim{P(X)}}}\bigg[\log{\frac{P(X,Z)}{P(X)\cdot{P(Z)}}}\bigg] \end{aligned}\]우리는 MI는 KLD와 매우 밀접한 관련이 있음을 알 수 있습니다. 즉, VAE에서 KLD 항을 최소화 하는 것은 $x$ 와 $z$ 사이의 MI를 최소화 하는 것과 같습니다. 여기서 MI가 만약 최소화되어 0이 된다는 것은 두 random variable이 독립이 된다는 것입니다.
결론적으로 VAE는 $\log{p(x)}$ 를 최대화 하는 과정에서, KLD를 최소화하려 할 것입니다. 이 과정에서 만약 극단적으로 KLD가 0이 된다면 $x$ 와 $z$ 는 독립이 될 것이므로, reconstruction error가 커질 것이고 $\log{p(x)}$ 를 최대화 하지 못할 것입니다. 따라서 적당히 $x$ 와 $z$ 의 MI를 유지하는 선에서 KLD를 최소화 하기 위해서, 복원(reconstruction)에 상관없는 특징 정보부터 버릴 것입니다.
Anomaly Detection with Variational Autoencoders
이처럼 VIB는 훌륭한 regularizer로 오버피팅을 막아주며, 결과적으로 이것은 마치 주어진 상황에서 최적의 병목 구간 크기를 갖게 하는 효과를 갖습니다. VIB를 통해 VAE는 vanilla 오토인코더에 비해 훨씬 나은 성능의 이상탐지(anomaly detection) 성능을 제공합니다. 실험을 통해 우리는 기존의 AE는 너무 큰 bottleneck을 가지면 identity function이 되며 이상탐지 성능이 떨어지는 것에 반해, VAE는 bottleneck의 크기가 커질수록 이상탐지 성능이 오르는 효과를 갖는 것을 확인할 수 있었습니다. 따라서 AE 기반의 anomaly detection을 수행할 때, 기존에는 bottleneck의 크기를 hyper-parameter로 튜닝해야 했던 반면에, VAE의 경우에는 튜닝을 할 필요가 거의 없어졌습니다.
Anomaly Detection with Adversarial Autoencoders
Adversarial Autoencoders(AAE) [9]는 VAE 만큼 널리 쓰이는 오토인코더 중에 하나이며, 마찬가지로 anomaly detection에서도 널리 활용되고 있습니다. [10] VAE는 최적화 과정에서 KLD term을 작게 만들기 위해 latent distribution을 gaussian의 형태에 가까워지지만, 실제 gaussian 분포를 따르지는 않습니다. 하지만 AAE는 latent distribution을 검사하는 discriminator를 도입하여, 원하는 형태의 latent distribution을 강제시킬 수 있습니다. 이러한 특성은 unimodal normality 가정과 함께 쓰이면 $P(z)$ 를 구하는데 용이하게 사용될 수 있습니다. [10]
Summary
오토인코더는 고차원인 입력 차원에서 저차원인 병목 구간의 차원으로 맵핑 과정을 압축과 해제를 반복하며 학습합니다. 이 과정에서 information bottleneck이 만들어지게 되며, 자동으로 입력 샘플 복원을 위한 중요한 특징(feature)과 중요하지 않은 특징을 구분할 수 있는 능력을 학습합니다. — 이것은 매니폴드 가설에 의해서도 설명이 가능합니다. 하지만 정상 데이터만을 활용하여 고차원에서 저차원의 맵핑 과정을 학습하기 때문에, 잠재공간(latent space)의 정보를 활용하여 anomaly detection을 수행하는 것은 새로운 가정을 도입하는 것(unimodal normality)입니다. 따라서 보통은 잠재공간의 정보를 활용하지 않습니다. [8] 또한 VAE를 통해 anonamly detection을 수행하게 되면 VIB의 특성을 활용하여 가장 큰 hyper-parameter인 bottleneck 크기를 튜닝할 필요가 없어집니다. 추가로 $P(z)$ 를 활용하고자 할 때, AAE를 사용하게 되면 latent의 분포를 gaussian과 같은 형태로 강제할 수 있어, latent variable의 확률값을 구하는데 활용 가능합니다.
References
- [1] Stanislav Pidhorskyi et al., Generative Probabilistic Novelty Detection with Adversarial Autoencoders, NeurIPS, 2018
- [2] Lei et al., Geometric Understanding of Deep Learning, Arxiv, 2018
- [3] Tishby et al., The information bottleneck method, Annual Allerton Conference on Communication, Control and Computing, 1999
- [4] Kingma et al., Auto-Encoding Variational Bayes, ICLR, 2014
- [5] Tishby, Information Theory of Deep Learning, https://youtu.be/bLqJHjXihK8
- [6] Tishby et al., Deep learning and the information bottleneck principle, IEEE Information Theory Workshop (ITW), 2015
- [7] Alemi et al., Deep Variational Information Bottleneck, ICLR, 2017
- [8] Ki Hyun Kim et al., Rapp: Novelty Detection with Reconstruction along Projection Pathway, ICLR, 2020
- [9] Makhzani et al., Adversarial autoencoders. Arxiv, 2015.
- [10] Stanislav Pidhorskyi et al., Generative Probabilistic Novelty Detection with Adversarial Autoencoders, NeurIPS, 2018